


Most AI systems produce outputs without explaining how they got there. A credit application is denied. A resume is filtered out. A medical flag is raised. The model gave an answer, but the logic stayed hidden. That gap between output and reasoning is what explainable AI is designed to close, and it sits directly in the space where product teams make decisions about what to show users, how much to reveal, and what level of transparency is owed.
Explainable AI (XAI) is not a single feature or technique. It is a set of principles and practices for making AI behavior understandable to the people who depend on it. That includes users trying to make sense of a recommendation, designers deciding how to present AI output, and PMs writing requirements for systems that affect people's lives. Understanding these terms changes what product professionals ask for, what they notice when it is missing, and what they push back on when transparency is treated as optional.
The vocabulary in this lesson covers the core concepts: what a black box is and why it matters, how interpretability differs from explainability, what confidence scores communicate, how counterfactual and feature-based explanations work, and what trust calibration means for users who rely on AI in high-stakes situations. These are the terms that come up when engineers explain what a model can and cannot surface, and when designers argue for why it should.
Explainable AI (XAI)
Explainable AI (XAI) is the practice of making AI systems understandable to the people who use or are affected by them. It covers how a model communicates its reasoning, what it reveals about the factors behind its outputs, and how that information is presented in a way that supports human understanding and decision-making. The goal is not to expose all the technical details of how a model was built, but to give users and product teams enough visibility to evaluate whether the output makes sense.
The need for XAI has grown as AI systems have moved into higher-stakes decisions. When AI determines whether a loan is approved, a resume passes screening, or a medical image warrants follow-up, people need more than just an answer. They need enough reasoning to verify it, challenge it, or act on it. Without that, trust becomes guesswork. XAI addresses this by designing how models communicate, not just what they output.
For designers and PMs, XAI is not an engineering concern to hand off. It is a product decision about what to show and when. A designer working on a hiring platform needs to ask what explanation a rejected candidate deserves. A PM building a credit tool needs to specify what the system reveals about why a decision was made. These are design requirements, not afterthoughts, and they directly affect whether users trust the product enough to rely on it. [1]
Pro Tip! XAI is not about making AI simpler. It is about making AI's reasoning visible enough that humans can decide when to rely on it and when to question it.
Black box AI
A black box AI is a system whose internal decision-making process is not visible or interpretable to the people using it. The model receives inputs, produces outputs, and offers no readable explanation of what happened in between. The reasoning stays inside. For many high-performing models, including most neural networks and large language models, this is not a design choice: the complexity of the model itself makes it difficult even for its developers to trace exactly how a specific prediction was reached.
Black box behavior becomes a problem when the stakes of the output are high. In low-stakes contexts, such as a playlist recommendation or an autocomplete suggestion, the absence of explanation is rarely critical. In higher-stakes contexts, such as credit scoring, medical diagnosis, or hiring tools, operating without explanation creates real risk. Users cannot verify whether the output is accurate. Teams cannot identify where the model is failing. Organizations cannot demonstrate that the system is fair.
Understanding what a black box is, and what it limits, is the first step toward asking the right questions when evaluating AI-powered features: what does this model output, and what, if anything, can it say about why?[2]
Pro Tip! The problem with a black box is not that it might be wrong. It is that no one can tell when it is wrong, or why.
Model interpretability
Model interpretability is the degree to which the reasoning behind a model's outputs can be understood by humans:
- A highly interpretable model follows logic that people can read and follow: a decision tree that asks a series of yes/no questions, for example, produces outputs that users can trace step by step.
- A low-interpretability model, such as a deep neural network, produces outputs through processes so complex that even the people who built it cannot always explain a specific prediction.
Interpretability exists on a spectrum, and most product decisions involve tradeoffs within it. More interpretable models are easier to audit and explain, but they are often less accurate or capable than complex models. More powerful models produce better results in many cases, but the reasoning becomes harder to expose. For product teams, this tradeoff is not abstract: it comes up in decisions about which model to build on, what explanation features are possible, and what transparency the product can realistically deliver to users.
The practical implication for designers and PMs is that interpretability defines the ceiling of explainability. You cannot design an explanation layer that reveals reasoning the model does not have access to. A PM specifying an explanation requirement needs to ask: what does this model actually surface about its own decision process? A designer building a "why this result?" feature needs to understand whether the model can support that feature or whether the explanation will be a post-hoc approximation. Knowing the difference matters, because one is a true explanation and the other is a reasonable guess.[3]
Pro Tip! A model that explains itself is interpretable. A model that gets explained by a second system afterward is not — that is post-hoc rationalization.
Confidence score
A confidence score is a numerical or categorical value that an AI model outputs alongside its prediction to indicate how certain it is about that result. Rather than just returning an answer, the model returns an answer with a measure of how likely it believes that answer to be correct. A medical image classifier might flag an anomaly and report 92% confidence. A document classifier might categorize a support ticket and report 58% confidence. Both are predictions, but the level of certainty they carry is very different.
Confidence scores are rarely visible to users. They work behind the scenes, giving product teams a way to design around uncertainty. A high-confidence output might flow through automatically, while a low-confidence one gets routed to human review or suppressed entirely. The score is an input to a product decision, not a user-facing feature. A Gmail spam filter uses confidence to decide whether an email lands in the inbox or disappears into spam. A medical flagging tool might use it to determine whether a result goes straight to a doctor or triggers an additional check first. Users experience the consequences of those decisions without ever seeing the number behind them.
The difficulty with confidence scores is that they can be misread. A high score does not always mean the model is right: it means the model is confident, which is not the same thing. A model can be consistently confident and consistently wrong in a specific category. For designers, this means confidence displays require careful framing and user testing to ensure they communicate what they are actually measuring. A score that looks like a reliability guarantee can create misplaced trust if users do not understand what confidence means in the context of that specific model.[4]
Pro Tip! Showing a confidence score is only useful if users understand what it measures. A percentage they cannot interpret is noise, not transparency.
Counterfactual explanation
A counterfactual explanation tells users not just what the AI decided, but what would have needed to be different for the decision to change. Instead of explaining the internal logic of the model, it explains the output in terms of the conditions that produced it. The explanation does not reveal how the model works. It reveals what the model responded to, expressed in terms users can act on.
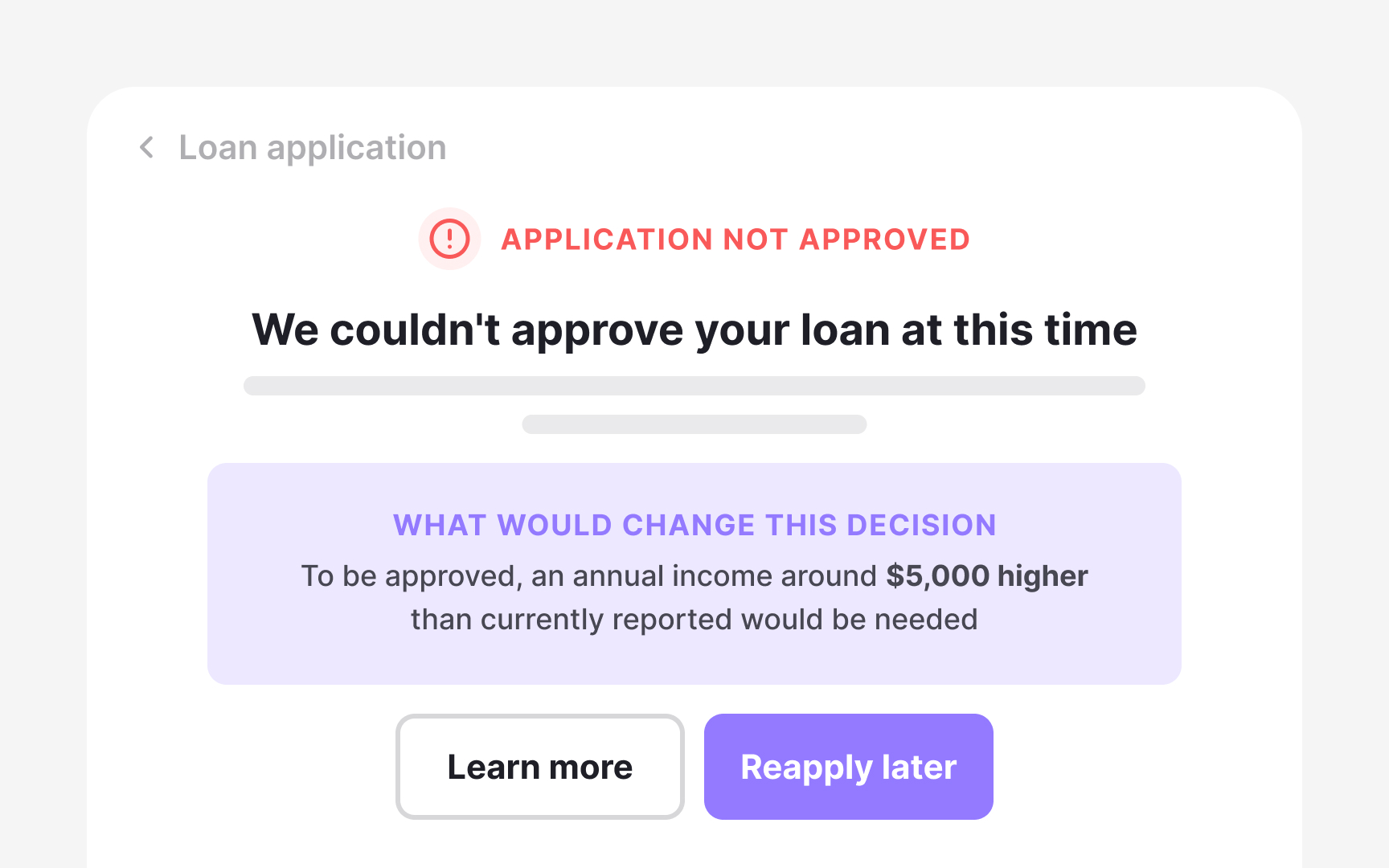
The most documented use case is loan denial. When a bank's AI system rejects an application, a counterfactual explanation tells the applicant not that the model scored them poorly, but what would need to be different for a different outcome: "To be approved, an annual income around $5,000 higher than currently reported would be needed." The model is not opening its internal logic. It is surfacing the specific condition that would flip the result, expressed in terms the applicant can actually act on. That shift from "here is what the system decided" to "here is what would change the decision" is what makes counterfactual explanations valuable.[5]
Pro Tip! Counterfactuals work best when they reference things users can change. Pointing to factors they cannot influence is not helpful, it is harmful.
Feature importance
Feature importance is a way of explaining an AI model's output by identifying which input variables had the most influence on a specific prediction or decision. When a loan model evaluates an application, many data points go in: income, credit history, employment status, debt levels, and more. Feature importance surfaces, which of those factors contributed most to the outcome. It answers not just "what did the model decide?" but "what did the model pay most attention to?"
For product teams, feature importance is one of the most accessible XAI concepts because it translates model behavior into plain language. Showing users a ranked list of factors that influenced their result, such as "Employment history, Credit score, and Recent payment behavior," is a concrete form of explanation. It does not require users to understand machine learning. It tells them what the system looked at. A streaming TV service showing "Because you liked X" is a consumer-facing version of this: the model is surfacing which input most influenced a recommendation.[6]
Pro Tip! Feature importance tells you what the model "looked at." If those factors do not make sense for the problem, the model has learned the wrong thing.
Model transparency
Model transparency is the degree to which an AI system makes its behavior, inputs, and decision logic available for review. A transparent model is one where the people using it or affected by it can find out what data it was trained on, what it optimizes for, and what rules or constraints shape its outputs. This is different from interpretability, which is about whether the model's internal mechanics can be understood. Transparency is about what the system is willing to disclose.
In product terms, model transparency often shows up as documentation: a system card that describes what a model does and does not do, a disclosure that content was AI-generated, or a statement that a recruiting tool does not use demographic data. Each of these is a transparency mechanism. They do not necessarily make the model's internal logic readable, but they make the system's behavior and limitations knowable. Designers who work on AI products are often the people responsible for where and how those disclosures appear.
Transparency matters because it shifts the basis of trust from assumption to information. Without it, users have no way to evaluate whether an AI system is appropriate for the task it is being asked to do. A user of an AI-powered financial tool who does not know what data the model uses cannot assess whether its recommendations apply to their situation. For product teams, transparency is not just an ethical stance: it is a design specification. Deciding what to disclose, to whom, and in what form is a product decision that affects how users form appropriate expectations about what the AI can and cannot do.[7]
Pro Tip! A model can be transparent, fully documented and disclosed, and still be a black box. Disclosure and interpretability are different things.
Trust calibration
Trust calibration is the process by which users develop an appropriate level of reliance on an AI system, enough to use it effectively, but not so much that they stop applying their own judgment. The goal is not maximum trust. It is accurate trust: users who understand what the system does well, where it is uncertain, and when they should verify or override its output. An AI product that users trust blindly is as poorly designed as one they distrust entirely.
Calibrating trust is an ongoing design challenge because it requires users to form accurate mental models of what the AI can and cannot do. A clinical tool that a doctor uses without question when the model is uncertain is dangerous. A safety alert system that operators routinely override because they trust their own judgment more has also failed. In both cases, the calibration is off: users’ actual behavior does not match what the situation calls for.
For product teams, trust calibration is shaped by what information the system surfaces and how. Confidence scores, explanation labels, audit trails, and override options all contribute to users' sense of how much reliance is appropriate.[8]
Pro Tip! Users who never question AI output and users who always ignore it have both failed to calibrate. The design goal is the middle: informed reliance.
Topics
References
- What Is Black Box AI and How Does It Work? | IBM
- What is Explainable AI (XAI)? | IBM
- People + AI Guidebook
- 15 Counterfactual Explanations – Interpretable Machine Learning
- Beyond The Black Box: Practical XAI For UX Practitioners — Smashing Magazine | Smashing Magazine
- Designing Trust in AI Products: UX Strategies for Product Leaders | Standard Beagle Studio | Standard Beagle
- People + AI Guidebook





