


Bias in AI does not announce itself. A hiring tool quietly screens out candidates from certain backgrounds. A facial recognition system performs worse on darker skin tones. A loan approval model produces different outcomes for people with similar financial profiles but different zip codes. These are documented outcomes from real products, built by teams who were not asking the right questions early enough.
What makes bias hard to address is that it rarely comes from bad intent. It enters AI systems through training data that reflects historical inequities, through design choices that optimize for the wrong metrics, and through features that serve as proxies for characteristics that were never meant to influence a decision. Knowing the vocabulary gives designers and product managers the language to ask those questions before a product ships rather than investigate complaints after it does.
Training data bias
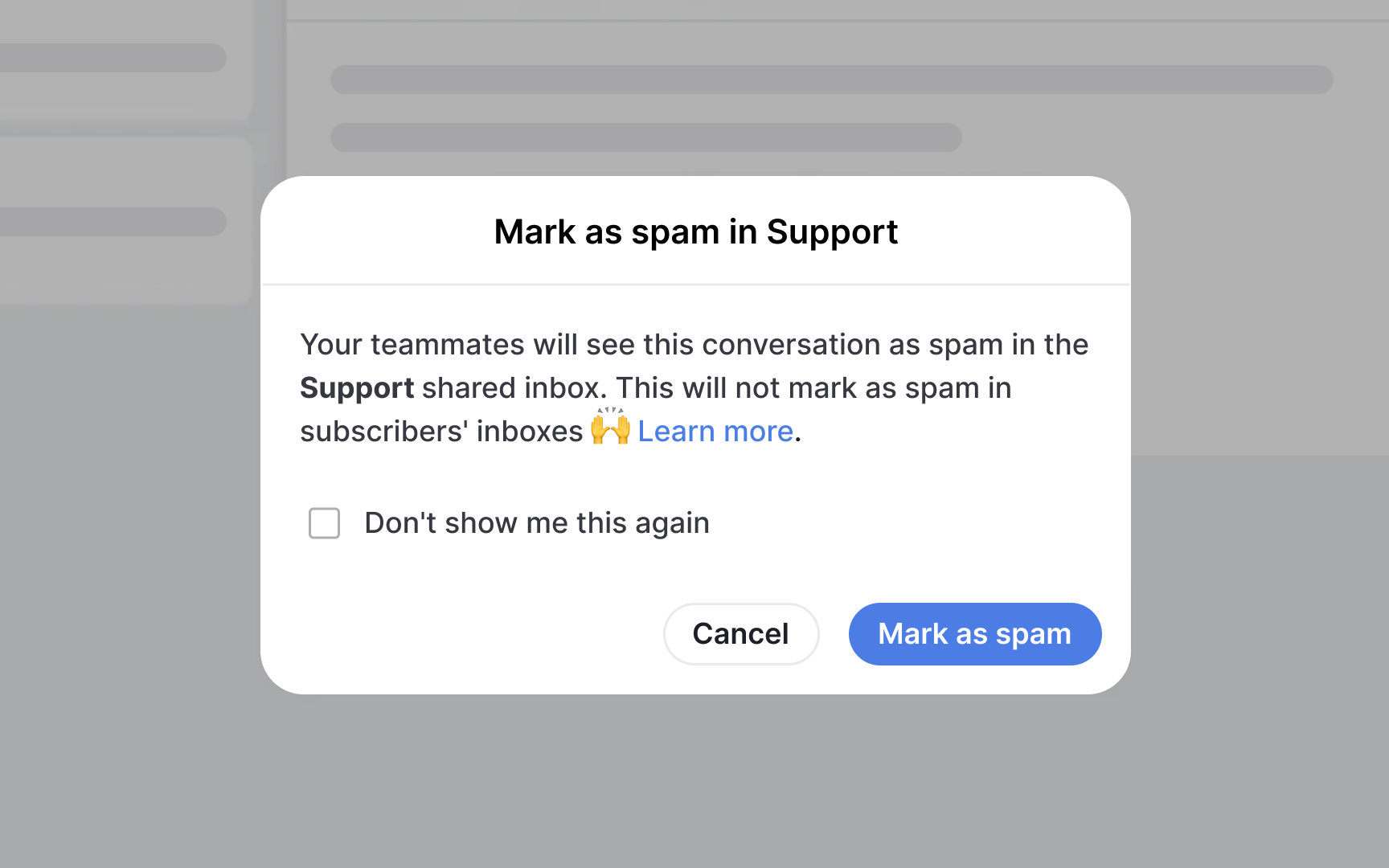
Training data bias occurs when the dataset used to train a model does not accurately represent the population to which the model will be applied. Machine learning models learn patterns from data rather than from rules, so the patterns they learn reflect whatever is already present in that data, including historical inequities, collection gaps, and representation imbalances.
A model trained on resumes from a company that historically hired mostly men will learn to associate male-coded language with successful candidates, not because that reflects merit, but because it reflects the past. A content moderation model trained predominantly on English-language data will perform worse on other languages. The model cannot distinguish a genuinely predictive pattern from one that is an artifact of how the training data was collected.
This matters because training data bias produces systems that perform differently across user groups, often disadvantaging those underrepresented in the data. Recognizing training data bias early, during requirements and design, means teams can ask the right questions before deployment rather than investigate failures after launch.[1]
Pro Tip! Asking "who is not in this dataset?" during requirements is more effective than investigating failures after launch.
Algorithmic bias
Algorithmic bias refers to systematic and unfair differences in how an AI model treats different groups. Unlike training data bias, which originates in the input data, algorithmic bias arises from decisions made in how a model is designed, what it is optimized for, and how its outputs are applied. A model optimized purely for overall accuracy may achieve that goal while performing worse for a smaller demographic group.
The distinction matters because the two require different responses. Improving data representation addresses training data bias. Changing the model's objective function, adjusting decision thresholds, or redesigning how outputs are applied addresses algorithmic bias. A credit scoring model might use zip code as a feature because it correlates with creditworthiness historically, without recognizing that zip code is also a proxy for race, a protected attribute.
Product managers and designers encounter algorithmic bias most directly when reviewing model performance across user segments. A system that works well overall but fails systematically for one group has an algorithmic bias problem, and fixing it requires more than collecting more data.[2]
Protected attributes in AI
Protected attributes are characteristics legally or ethically recognized as inappropriate bases for making decisions about individuals. In most jurisdictions, these include race, gender, age, religion, national origin, disability status, and sexual orientation. Models can make decisions that correlate with these characteristics even when the attributes are not explicitly included as inputs.
This indirect effect is called proxy discrimination. A model that does not receive race as an input might still produce racially disparate outcomes if it uses features strongly correlated with race, such as zip code, name, or certain browsing behaviors. For a designer working on an AI-powered lending or hiring product, knowing which features might serve as proxies for protected attributes is essential for flagging risk during the design phase.
Many regions now require organizations to test AI systems for disparate impact on protected groups, even when those groups are not explicitly used as inputs. Knowing what protected attributes are and why proxy discrimination is a genuine technical risk is the vocabulary baseline for participating in compliance conversations.[3]
Pro Tip! Proxy discrimination is one of the most common ways bias enters AI systems in practice. Zip code, name, and browsing behavior are all examples worth auditing.
Disparate impact in AI
Disparate impact occurs when an AI system produces outcomes that disproportionately disadvantage a group, even when not designed with that intention. The term comes from civil rights law, where it refers to neutral-seeming policies with unequal effects on protected groups. In AI, disparate impact is the measurable outcome of bias: the gap in approval rates, error rates, or outcomes between groups.
A loan approval model with no explicit reference to race might still show lower approval rates for one racial group than another with similar financial profiles. A hiring algorithm using graduation year may inadvertently disadvantage older candidates. The intent of the system does not eliminate the harm. What matters, legally and ethically, is the measurable difference in outcomes.
Disparate impact analysis is among the most concrete tools for AI bias testing. By comparing model outputs across demographic groups, teams can identify where a system produces unequal results and whether those differences are justified or the product of bias. Requiring this analysis before launch is a practical requirement for product managers defining AI feature acceptance criteria.[4]
Bias audit
A bias audit is a structured evaluation of an AI system to assess whether it produces unfair or discriminatory outcomes across different groups of users. Unlike general model testing, which focuses on overall accuracy, a bias audit specifically examines model behavior across demographic segments, such as gender, race, age, or disability status, to determine whether outputs differ in unjustified or harmful ways.
Bias audits compare key metrics across groups: error rates, false positive rates, false negative rates, and approval rates. For a content recommendation system, an audit might check whether certain content categories reach specific groups disproportionately. For a hiring tool, it would compare screening rates across gender and racial groups. Finding a gap requires explaining why it exists and whether it reflects something legitimate.
Regulations like the New York City Local Law 144, which requires bias audits for automated employment decision tools, are making these evaluations a legal requirement in some jurisdictions. For product managers, building a bias audit into the AI feature launch process is no longer optional in regulated contexts.[5]
Pro Tip! NYC Local Law 144 (2023) was the first US law requiring bias audits for AI hiring tools. It is widely watched as a template for similar legislation elsewhere.
Bias mitigation strategies
Bias mitigation strategies are methods used to reduce unfair outcomes in AI systems. They apply at 3 stages of model development: before training, during training, and after training. Each approach addresses bias at a different point in the pipeline and involves different tradeoffs:
- Pre-processing strategies modify training data before the model sees it, for example, by resampling underrepresented groups or removing proxy features.
- In-processing strategies modify the model itself, adding fairness constraints so the model is penalized for producing disparate outcomes.
- Post-processing strategies adjust outputs after predictions are made by applying different decision thresholds for different groups.
None of these strategies eliminates bias entirely. Resampling can reduce accuracy on the dominant group. Adding fairness constraints can decrease overall performance. Post-processing can introduce new inconsistencies. For a product manager reviewing a vendor's bias claims, knowing which strategy category was used and what tradeoffs were accepted is essential for evaluating whether the approach fits the product's context.[6]
Representational harm in AI
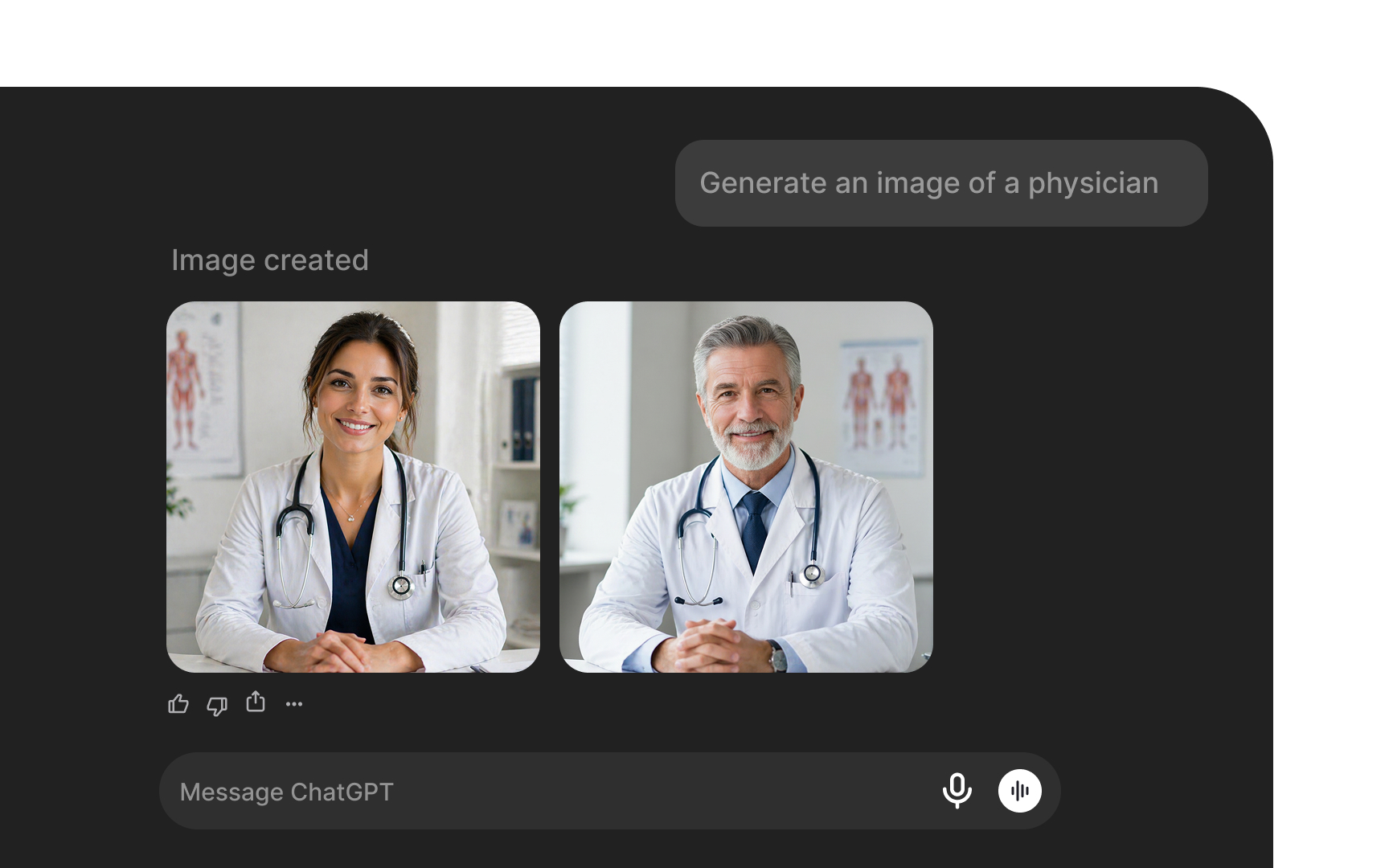

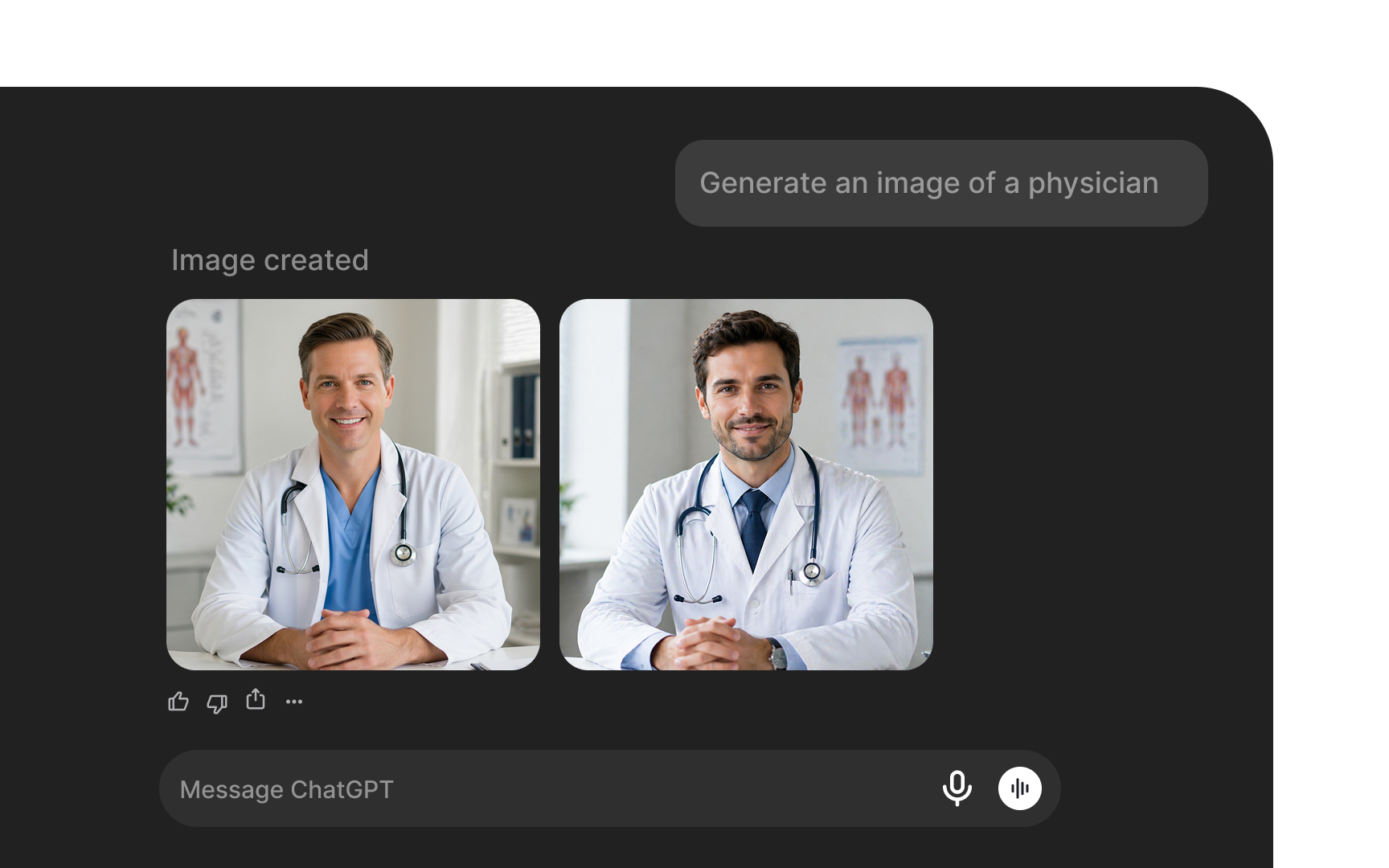

Representational harm occurs when an AI system produces outputs that demean, stereotype, or erase a particular group. Unlike allocation harms, which involve a group being denied a resource, representational harms affect how groups are portrayed and characterized in model outputs. Both are forms of bias, but they manifest differently and require different responses.
A text-to-image model that consistently depicts doctors as male and nurses as female is producing representational harm. A language model that generates stereotyped associations between certain ethnic names and negative attributes causes it. In each case, the model is encoding and amplifying social biases present in its training data, shaping how users perceive the groups depicted.
Representational harm matters because it affects real users in ways beyond incorrect predictions. A system that systematically misrepresents a group undermines trust and can cause genuine harm to those affected.[7]





