


Product decisions made without evidence tend to feel fast and age poorly. Discovery exists to close that gap, but not all discovery is created equal. A five-minute customer interview and a full beta test are both forms of evidence. What separates them is the level of certainty each one earns, and what kind of decision it is appropriate to inform. This is the core idea behind the truth curve: as your research methods become more experiential and closer to real product behavior, the more you can trust what you learn. Early, lightweight methods like surveys and paper prototypes are cheap and fast. They are best suited to testing whether a problem is real. Higher-fidelity methods like live betas and A/B tests are slower and more expensive. They are best suited to testing whether the solution works at scale. Reaching for the wrong method at the wrong stage is one of the most common and costly mistakes in discovery.
Signal quality also matters. A whale client demanding a feature is not a product strategy. A "yes" from a friend in an interview is not validation. These are the false positives that quietly distort roadmaps. Evidence-based discovery means developing the judgment to know when you have enough signal to act, and when you are still just confirming what you already believed.
How the truth curve maps research confidence
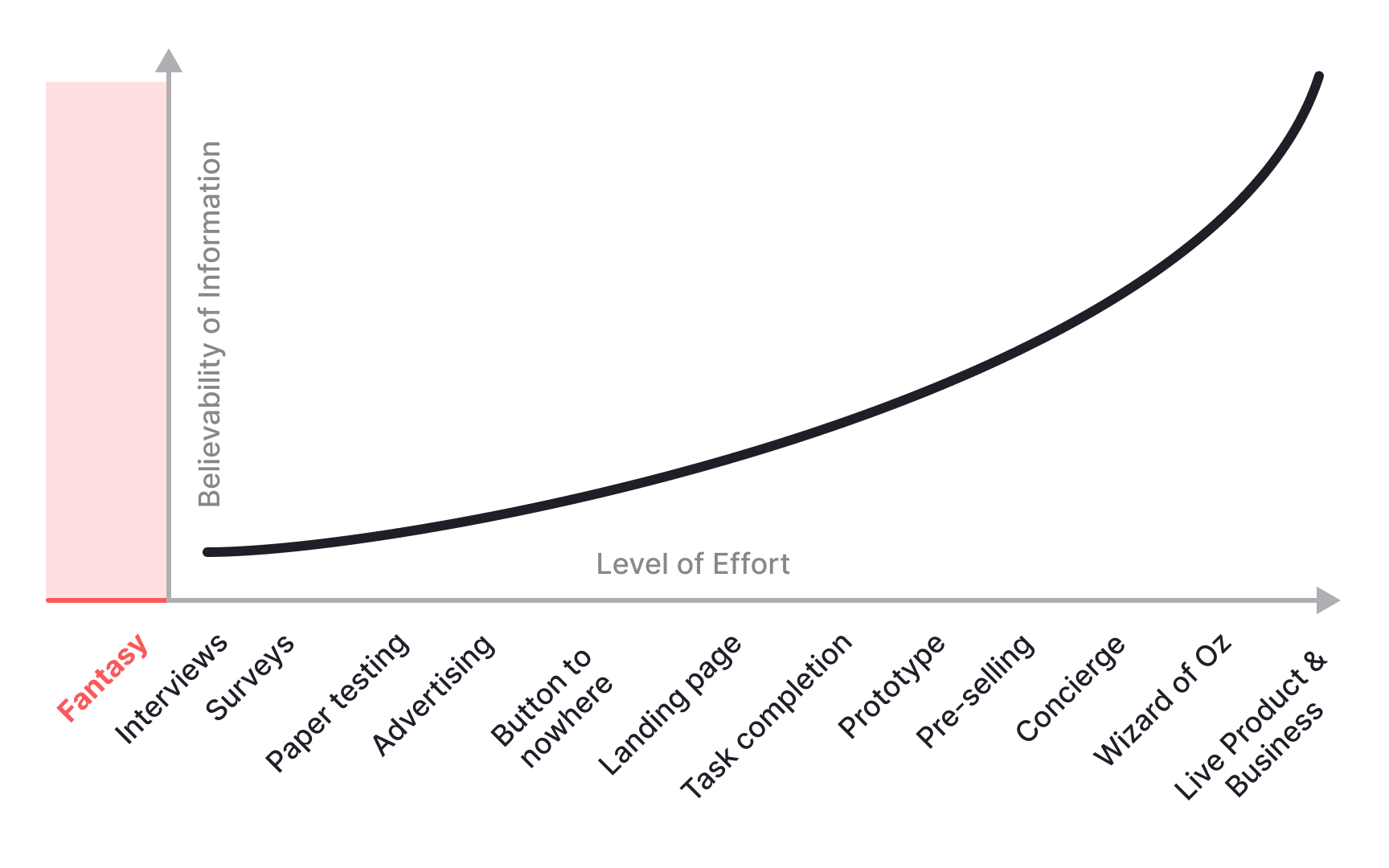
The truth curve maps research methods by how much you can trust what they tell you. On one end are lightweight, fast methods like surveys, customer interviews, and paper prototypes. These are cheap and easy to run, but they require you to filter the results through your own judgment. A user saying "I would definitely use this" in an interview is not the same as a user paying for it in production.
On the other end of the curve are live bets: a product in the market with real metrics. This is the strongest form of truth, because you are observing actual behavior rather than stated intent. The challenge is that you cannot wait for a fully built product to start learning. The curve exists to help you find the right method for where you are in the process.
The further along the curve you move, the more experiential the test becomes. A clickable mockup is more believable than a paper sketch. A concierge MVP, where a person manually delivers the service behind a simple interface, is more believable than a mockup. A live beta with a real cohort is more believable than all of them. The key judgment call is not "which method is most rigorous" but "which method gives me enough certainty to make this specific decision."[1]
Pro Tip! The earlier you are on the truth curve, the more your own judgment has to compensate for what the method cannot verify.
Match research fidelity to the question you are testing
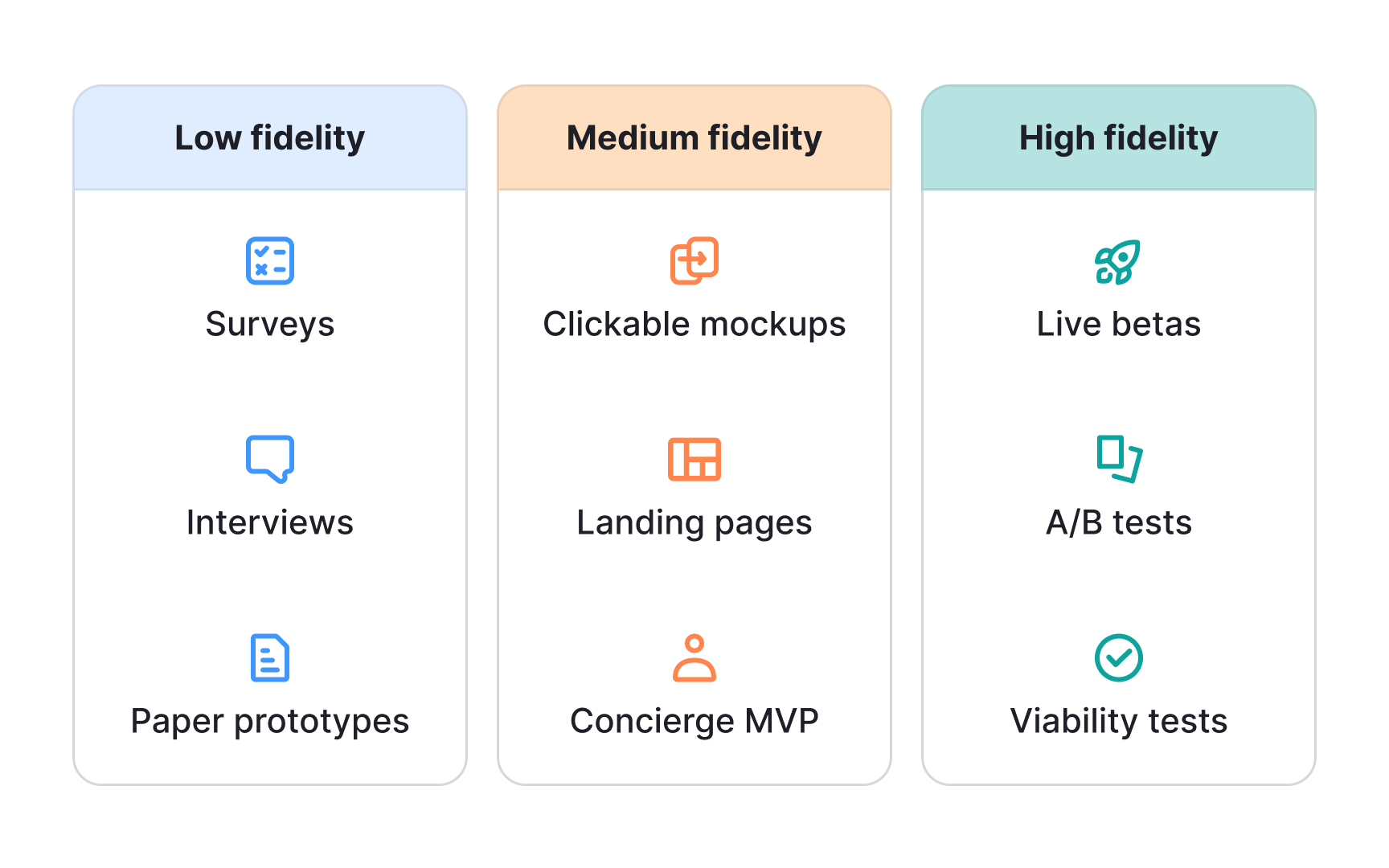
Discovery methods fall into 3 broad fidelity levels, and each one is suited to a different question:
- Low-fidelity methods, including surveys, customer interviews, and paper prototypes, are designed for testing the problem. They answer the question: do people actually care about this? They are fast and inexpensive, which makes them the right starting point before any meaningful investment.
- Medium-fidelity methods, including clickable mockups, landing page tests, and concierge MVPs, shift the focus to the solution. They test whether users can understand and engage with what you are proposing. A landing page test, for example, can tell you whether users are interested enough to take the next step. A concierge MVP lets you deliver the experience manually before writing a single line of code.
- High-fidelity methods, including live betas, A/B tests in production, and full builds, test viability and scale. They answer the hardest questions: will users pay for this, and does it hold up when real people use it under real conditions? These methods produce the most trustworthy signal, but they are also the most expensive to run.
Matching the method to the question you are asking is what separates disciplined discovery from discovery that just generates activity.
Combine qualitative and quantitative data in product decisions
Quantitative data tells you what is happening. It comes from analytics, transactions, click data, and surveys with large sample sizes. It is hard to argue with. If 60% of users drop off at a specific step in your onboarding flow, that number is not a matter of interpretation.
Qualitative data tells you why it is happening. It comes from customer interviews, open-ended survey responses, support tickets, and sales call notes. It is richer and more contextual, but it requires more careful handling. One frustrated user venting in an interview is not a product insight. A pattern of the same frustration across thirty interviews might be.
The trap most product teams fall into is treating one type as superior to the other. A team that is purely data-driven will keep optimizing the onboarding step without ever understanding why users are confused there. A team that is purely customer-obsessed will build features for the loudest voices without checking whether those voices represent anyone else. The stronger approach is to cross-check both. When quantitative and qualitative data point to the same conclusion, that is a green light. When they conflict, that is a signal to pause and run a new experiment before committing resources.[2]
Pro Tip! Treat conflicting data as a sign that you do not yet understand the situation well enough to build.
Filter customer requests by pattern, not urgency
Not every customer request is a product signal. In B2B environments, especially, the loudest voice in the room is often a single large client or an executive who uses the product once a quarter. Their requests carry urgency, but urgency is not the same as strategic value.
A useful filter is to ask whether what you are hearing is a pattern or an anecdote. If a request appears once, it is noise. Put it in an icebox and wait to see if a second signal emerges. If the same request appears across multiple sources, like support tickets, sales calls, and user interviews, that is a pattern worth investigating. Volume is not the only signal, but it is a meaningful check against anecdote-driven roadmaps.
A second filter is to ask whether the request is a blocker or a nice-to-have. A feature that prevents a user from completing their core task is categorically different from one that makes their experience more pleasant. Blocking issues erode retention. Nice-to-haves are often forgotten by the time the feature ships. Separating these two categories before any prioritization conversation protects your roadmap from being hijacked by whoever made the most noise last week.[3]
Ask about past behavior to avoid false positives in interviews




When you ask users, "Would you use this feature?", they will almost always say yes. They want to be helpful. They do not want to disappoint you. This is a false positive, and it is one of the most common reasons product teams build things nobody uses.
The Mom Test, a concept from Rob Fitzpatrick, an entrepreneur and author whose work is taught at Harvard, MIT, and UCL, offers a different approach. The idea is to ask questions that even your mother, who wants to protect your feelings, cannot lie to you about. That means asking about real past behavior instead of hypothetical future intent. "Tell me about the last time you had to deal with this problem," gives you something verifiable. "Would you pay $20 for a tool that did this?" gives you a polite guess.
3 principles define the approach:
- Ask about their life, not your idea.
- Ask about specifics in the past, not hypotheticals in the future.
- Listen for problems, not solutions. Users are often excellent at describing pain. They are rarely reliable at prescribing the fix. When you let them pitch you their preferred solution, you lose the most valuable part of the conversation.[4]
Pro Tip! Users are good reporters of what they have done. They are poor predictors of what they will do. Ask accordingly.
Use proxy metrics to measure outcomes that resist direct tracking
Some of the most important things a product can do are difficult or impossible to measure directly. Trust, happiness, perceived quality, and brand loyalty are real outcomes that drive retention and revenue, but none of them appear in a dashboard. To make decisions involving these outcomes, product managers use proxy metrics.
A proxy metric is a measurable indicator that reliably predicts a more important but harder-to-capture outcome. For example, a product team that wants to improve long-term retention might track how quickly new users reach their first meaningful action in the product. Early activation does not equal retention, but there is a documented correlation between the two. Moving the proxy is a practical stand-in for moving the outcome you actually care about.
Effective proxy metrics share a few characteristics:
- They move quickly enough to inform sprint-level decisions.
- They are within the team's control.
- They have a strong correlation to the outcome they represent, ideally backed by historical data.
- They are simple enough that the team can track them without significant extra infrastructure. A proxy that requires more effort to measure than it saves in learning is not a useful one.[5]
Test demand before building with a fake door experiment
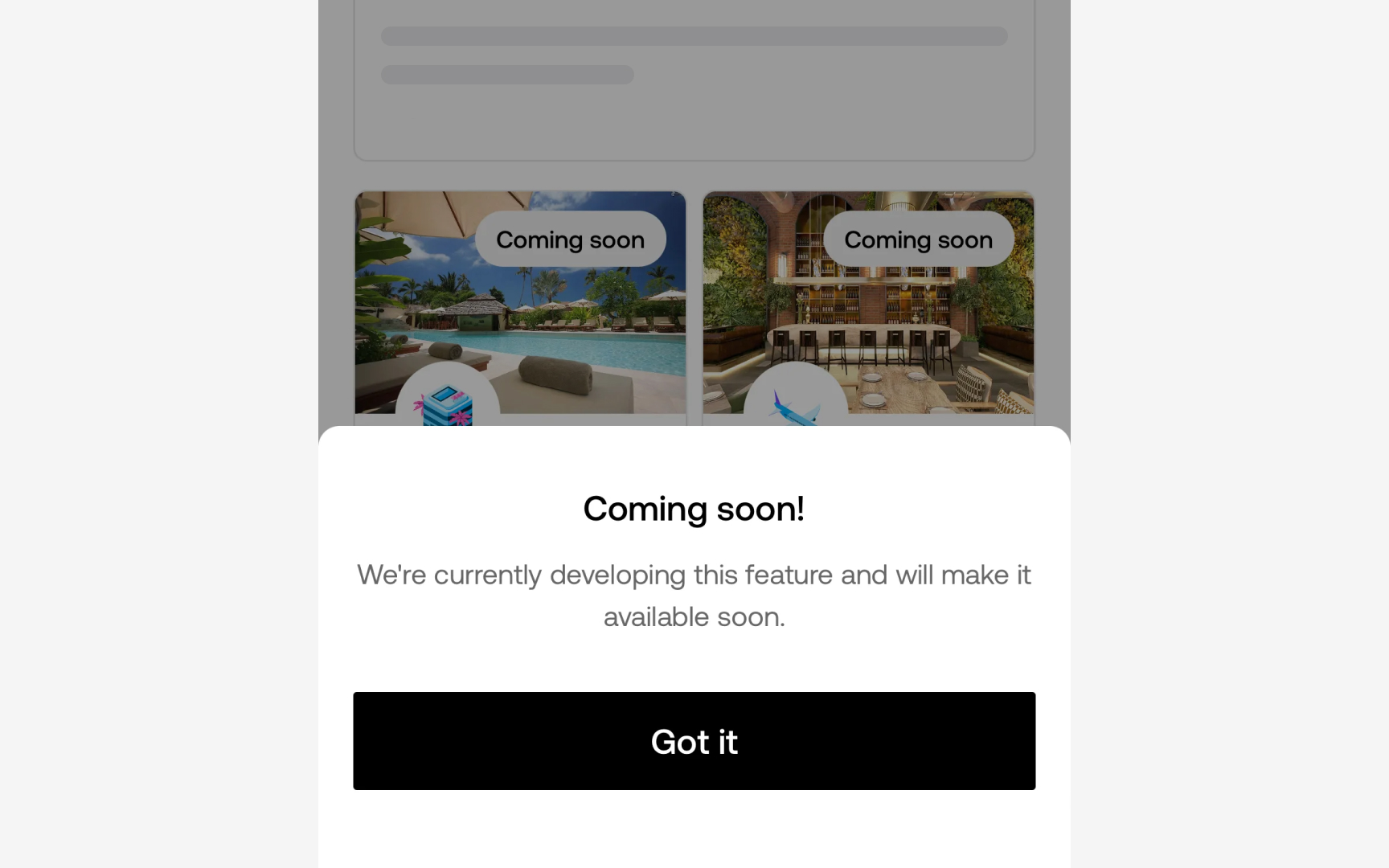
A fake door test, also called a painted door test, creates the appearance of a feature without building it. The most common form is a button, link, or call-to-action that looks like a real product path. When users click, they see a message explaining that the feature is not available yet. The click-through rate becomes a measure of genuine interest.
What makes fake door tests valuable is that they measure behavior, not stated intent. A user who tells you they want a feature in an interview may behave differently when the actual choice is in front of them. The fake door puts something real in the user's context and observes whether they reach for it.
The method has a meaningful limitation. A high click-through rate confirms that users are interested enough to take an action. It does not confirm that the feature will satisfy the underlying need, that users will keep using it, or that the execution will work. Fake door tests reduce the risk of building something nobody wants. They do not replace usability testing or post-launch validation. Used at the right moment, they are one of the cheapest and fastest ways to test demand before a single line of code is written.
Build continuous discovery as a team habit, not a project phase
Most product teams treat discovery as something that happens before building. They schedule a research sprint, talk to users, write up findings, and then return to execution until the next planning cycle. This is episodic discovery. It produces insights that are accurate at the time but go stale quickly. By the time a team is making decisions six months later, the research that informs those decisions may no longer reflect reality.
Continuous discovery works differently. Rather than running discovery as a phase, the team integrates lightweight customer contact into its regular weekly rhythm. Short interviews, quick feedback sessions, and ongoing observation become habits rather than events. The result is that insights stay connected to the current product questions, and no single research session carries the pressure of being definitive.
The practical challenge is that continuous discovery requires scheduling infrastructure and discipline that many teams underestimate. It is easy to skip customer interviews when a sprint is under pressure. The teams that sustain it treat it the same way they treat sprint planning: a non-negotiable cadence, not an optional activity. The payoff is that decisions are made with fresher signals, and the team builds a cumulative understanding of customers that no one-off research project can replicate.[6]





