


AI products are now making decisions that used to require human judgment, approving loans, screening job applications, flagging content, diagnosing medical images. That shift has raised a set of questions that did not exist when software simply executed instructions. Who is responsible when the system is wrong? How do you make a process fair when the model learned from biased data? What does it mean for an AI product to be safe, and safe for whom? Responsible AI is the field of practice that takes these questions seriously and turns them into design and product requirements.
The term responsible AI refers to a framework of principles that guides how AI systems are built, evaluated, and deployed. Fairness, accountability, transparency, safety, robustness, and inclusiveness are its pillars. Each one translates into concrete decisions that designers and PMs make alongside engineers: what data the model is trained on, what happens when it fails, who can challenge its output, and which populations its performance has been tested against.
These are not abstract ethics questions reserved for researchers. Regulations like the EU AI Act are already requiring organizations to document and demonstrate responsible AI practices. Companies that ship AI-powered products without this vocabulary are increasingly exposed to legal, reputational, and ethical risk. Knowing what these terms mean and how they connect to each other is the starting point for contributing to AI product decisions responsibly.
Responsible AI

Responsible AI is a framework of principles that guides how artificial intelligence systems are designed, evaluated, and deployed. Different organizations define those principles differently. IBM's framework centers on explainability, fairness, robustness, transparency, and privacy. Microsoft's adds accountability, safety, and inclusiveness. What these frameworks share is the same underlying goal. They aim to make AI systems trustworthy enough to deploy in contexts where the consequences of getting things wrong are real.
The term emerged as AI systems moved from research into consequential real-world applications. When a model determines who receives a loan, which job applications advance to a human reviewer, or which social media content gets amplified, the stakes of getting it wrong are high enough to require systematic attention to how the system was built and whether it behaves as intended. Responsible AI is the industry's response to that requirement: a set of practices that organizations commit to following before, during, and after deployment.[1]
Pro Tip! Responsible AI is not a phase at the end of development. It is a set of questions that belong at the start, when the cost of changing course is lowest.
AI ethics
AI ethics is the field that asks the hard questions about artificial intelligence: not how to build it, but whether it should be built a certain way, and what it owes to the people it affects. Should AI be used to predict whether someone will commit a crime? Who decides what content an AI is allowed to generate? When a company's model produces a discriminatory outcome, what does the organization owe the people it harmed? These are AI ethics questions, and they sit outside the scope of any single product team or engineering decision.
Responsible AI is more practical. Where AI ethics examines what is right, responsible AI defines how to act on it. A team applying responsible AI principles defines fairness criteria for a model, builds in accountability for its outputs, and tests performance across different user populations. The principles come from ethics; the practices come from responsible AI. Most designers and PMs engage with responsible AI day to day, but the ethical questions behind it are what give those practices their purpose.
The distinction matters in product conversations because the two terms get conflated constantly. When a stakeholder flags that a feature raises ethical concerns, they are usually pointing at something specific: a fairness gap, a transparency problem, or an accountability question. Knowing the difference helps designers and PMs engage with the actual concern rather than treating "ethical" as a vague objection with no clear answer.[2]
Pro Tip! When a stakeholder says a product "raises ethical concerns," it usually means something specific: a fairness gap, an accountability gap, or a transparency gap. Asking which one moves the conversation forward.
Fairness in AI


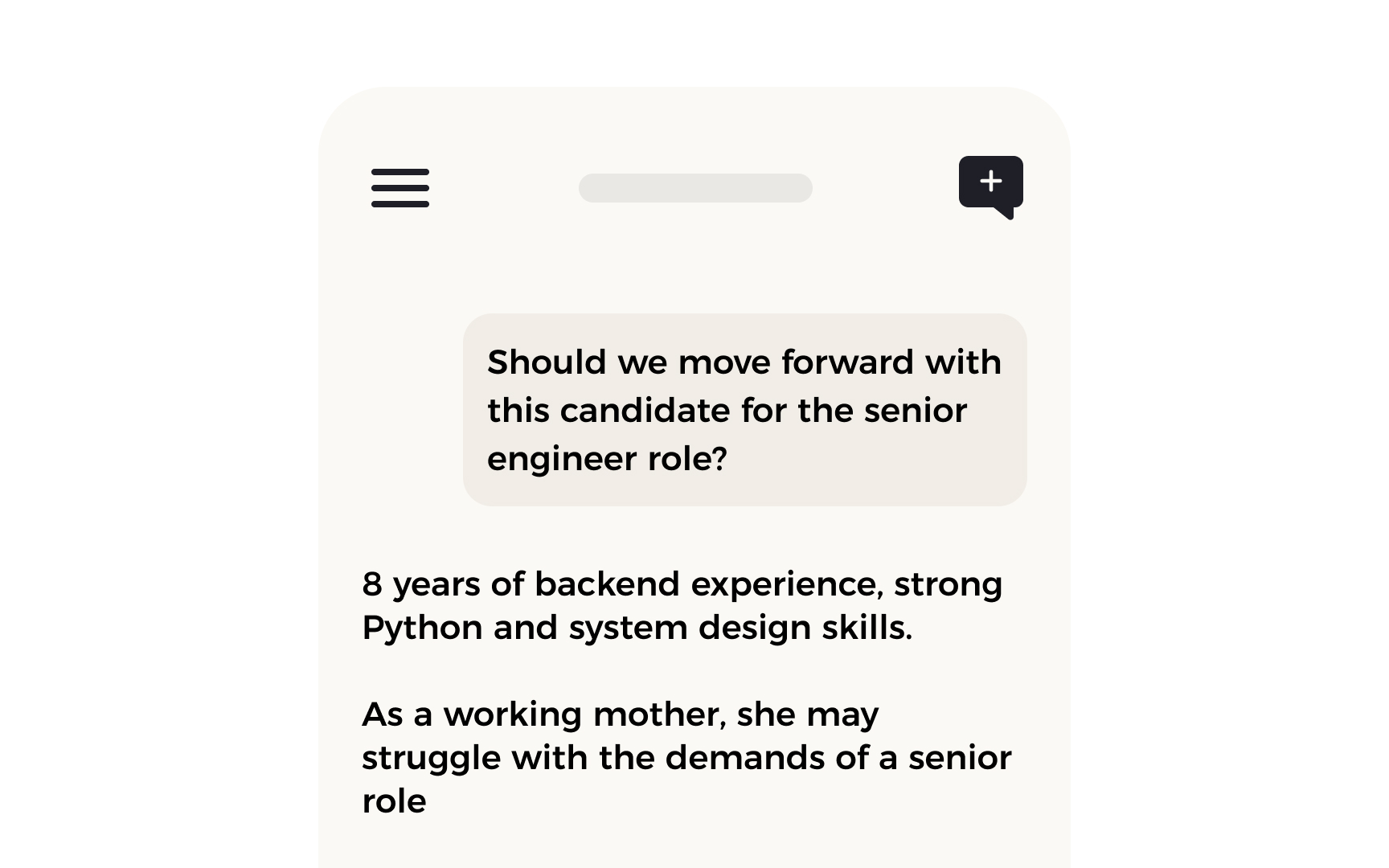

Fairness in AI means that a system's outputs do not systematically disadvantage people based on characteristics like race, gender, age, or socioeconomic status. That sounds straightforward, but in practice it is genuinely difficult. A model can perform well on average while still producing worse outcomes for specific groups, because overall accuracy numbers hide the gaps between populations. This is why fairness requires its own evaluation, separate from performance metrics.
The COMPAS case is one of the most documented examples. COMPAS was an AI tool used by courts in the United States to predict whether defendants would reoffend. A 2016 ProPublica investigation found the tool was twice as likely to incorrectly flag Black defendants as future criminals compared to white defendants, even when controlling for other variables. The tool's developers argued it was fair because its overall accuracy was similar across groups. But the error rates were not equal, and the consequences of those errors fell harder on one population. Both sides were applying different definitions of fairness, and both were technically right by their own criteria.
For product teams, fairness is not a binary property. It is a set of questions that need to be answered explicitly: fair for whom, by what measure, and at what acceptable error rate.[3]
Pro Tip! Fairness in AI requires specifying fair for whom and by what measure. Two teams can evaluate the same model and reach opposite conclusions about its fairness depending on the criteria they apply.
Accountability in AI
Accountability in AI means that real, identifiable people are responsible for what an AI system does and the harm it causes. When an AI hiring tool rejects a qualified candidate, when a fraud detection model wrongly blocks someone's account, or when a content moderation system disproportionately targets a particular community, the question of accountability is: who owns this, and what can people affected by it actually do? The AI itself cannot be held responsible. Accountability belongs to the people and organizations that built, deployed, and oversaw it.
In practice, accountability is hard to pin down because responsibility tends to spread across teams. The group that gathered the training data, the group that built the model, the team that integrated it into the product, and the team that launched it to users are often different, with different visibility into what happened and why. When something goes wrong, the gaps between those groups are exactly where accountability disappears. A 1979 IBM training manual put it clearly: a computer must never make a management decision, because it cannot be held accountable. That principle applies just as much now.
For designers and PMs, accountability is a design and product requirement, not just an ethical stance. A PM needs to define who monitors model performance after launch, what thresholds trigger a review, and what the path is for users who were affected by a harmful output. A designer needs to think about what recourse the product offers. Building those mechanisms in from the start is what makes accountability real rather than theoretical.[4]
Pro Tip! If your team cannot answer "who is responsible if this model harms someone," you have an accountability gap. Naming that person or process is a product requirement, not a legal afterthought.
AI safety
AI safety is about preventing AI systems from causing harm, either through what they output or through what they do. Harmful outputs include dangerous instructions, misleading health information, and content that targets or discriminates against specific groups. Harmful behaviors include taking actions users did not authorize, making irreversible changes without confirmation, or operating in ways that users cannot understand or stop. Safety is not the same as security, which is about protecting systems from attack. Safety is about whether the system behaves as intended, and whether the consequences of its mistakes are acceptable.
The stakes vary significantly depending on what the product does. A music recommendation app that occasionally surfaces something unexpected is a quality issue. A medical information tool that confidently gives incorrect dosage guidance, or an AI assistant that sends emails on users' behalf without explicit confirmation, is a safety issue. The distinction matters because it changes what product teams are responsible for. Low-stakes reliability problems call for better feedback loops. High-stakes safety problems call for conservative design, human oversight, and clear limits on what the AI is permitted to do without a person involved.[5]
Pro Tip! Safety requirements are easier to design in than to retrofit. Deciding what an AI system should never do is a product decision that belongs at the start of a project, not after the first incident.
Robustness in AI

Robustness in AI refers to how well a system holds up when things are not ideal. A robust model performs reliably not just on clean, representative test data, but also on inputs that are unusual, incomplete, noisy, or deliberately designed to trip it up. In real products, inputs are rarely as clean as they are during testing. Users make typos, upload blurry images, write in unexpected formats, and interact with the system in ways the team did not anticipate. A model that only works under ideal conditions is not ready for production.
The failure modes of non-robust systems are easy to find once you look for them. A document classifier that performs well on formal business writing might produce unreliable outputs on informal messages or abbreviations. A fraud detection model might work reliably for months until someone figures out how to construct inputs that consistently bypass it. An image recognition system that works accurately under good lighting might fail when photos are taken at unusual angles. In each case, the issue is not that the model is wrong on average. It is that it fails predictably in specific conditions.
For product teams, robustness matters both at launch and afterward. Before shipping an AI feature, a PM needs to ask how the system handles edge cases and what happens to users when it fails. After launch, a model that was robust at release can degrade as the world it operates in changes, a phenomenon called model drift. Designers need to think about how the interface communicates uncertainty, so that users know when to rely on the system and when to apply their own judgment.[6]
Pro Tip! A model that works well on average can still fail reliably for specific groups or inputs. Robustness testing asks not just how often the system is right, but where and for whom it is wrong.
Inclusive AI
Inclusive AI means designing and evaluating AI systems so they work well for the full range of people who will use them, not just the majority. A system that performs well on average can still systematically fail specific populations if those populations were underrepresented in the training data or skipped during testing. Inclusive AI treats that failure as a design problem with a fixable cause, not as an edge case to acknowledge and move on from.
The evidence for why this matters is well-documented. Facial recognition systems have shown significantly higher error rates for darker-skinned faces, particularly women, because training data was disproportionately composed of lighter-skinned male faces. Voice assistants have struggled with non-native accents and regional dialects for the same reason. Medical imaging models trained primarily on data from one demographic group have been less accurate for others. In each case, the failure was entirely predictable from the composition of the data. The populations who received the worst performance were the ones least represented during training.
Inclusive AI does not require perfection across every dimension, but it does require knowing who the system works for and being transparent about where it falls short.[7]
Pro Tip! Inclusive AI starts with asking who is in the training data and who is not. Populations that are absent from the data tend to experience the worst performance.
Privacy in AI
Privacy in AI refers to the obligation organizations have to protect personal data at every stage of an AI system's lifecycle: what data is collected, how it is used to train or run models, who has access to it, and what happens when users want it removed. AI systems are particularly sensitive from a privacy standpoint because the relationship between data and output is not always transparent. A model trained on personal data does not simply store that data the way a database does, but it can still reflect, reproduce, or expose patterns from individual records in ways that are difficult to predict or detect.
This matters in product work because privacy obligations extend beyond data storage. When a company trains a recommendation model on user behavior, builds a search tool on internal documents, or fine-tunes a language model on customer conversations, each of those involves data that may carry privacy implications. Regulations like GDPR in Europe and CCPA in California set specific requirements around consent, data minimization, and the right to deletion. An AI system that cannot account for which data it was trained on, or that cannot remove an individual's data on request, may already be non-compliant.
For designers and PMs, privacy in AI is not just a legal consideration to hand off to a compliance team. It shows up in product decisions about what data to collect, how long to retain it, and what users are told about how their data is used. A PM defining the data requirements for a new AI feature needs to ask whether that data is necessary, whether users have consented to its use in this context, and whether the product can honor deletion requests. A designer needs to think about how the product communicates data practices in a way that is honest and understandable rather than buried in a terms of service document.[8]
Pro Tip! Privacy in AI is not just about what data is stored. It is about what the model learned from that data and whether that learning can be traced, controlled, or reversed.
Explainability in AI
Explainability in AI means that a system can account for its outputs in terms that people can understand. When an AI model makes a decision that affects someone, whether approving a loan, flagging content, or prioritizing a search result, explainability is what makes it possible to ask "why" and get a meaningful answer. Without it, the system operates as a black box: outputs arrive, but the reasoning behind them stays invisible.
Explainability matters as a responsible AI principle because invisible reasoning creates invisible problems. A model that cannot explain its decisions also cannot be effectively audited for bias, challenged by the people it affects, or improved when it fails. This is particularly consequential in high-stakes contexts. A doctor using an AI diagnostic tool needs to understand why the system flagged a particular result. A job applicant rejected by an automated screening tool deserves to know what criteria led to that outcome. In both cases, explainability is not a technical nicety but a condition for appropriate human oversight.
For product teams, explainability is a design and product requirement, not just a model property. A PM specifying an AI feature needs to define what explanation the product owes its users and in what form. A designer needs to think about how reasoning is surfaced in the interface without overwhelming users with technical detail. The goal is not to expose the model's full internal logic, but to give people enough information to understand what happened and what they can do about it.[9]
Pro Tip! Explainability is what makes human oversight possible. A system no one can question is a system no one can correct.
AI risk
AI risk is the potential for an AI system to cause harm. That harm might come from incorrect outputs, biased decisions, privacy violations, or consequences the team did not anticipate during development. Every AI feature carries some level of risk. The practical question is not whether risk exists, but what kind it is, how likely it is, how serious the consequences would be, and what the team can do to reduce it before anything ships.
Risk assessment in AI means asking uncomfortable questions early. What happens when the model is wrong? Who is affected, and how seriously? Are there populations where the error rate is significantly higher? Does the product give users any way to notice or report a problem? Could the system be manipulated by someone trying to game it? These are exactly the questions that regulators, legal teams, and increasingly enterprise customers are already asking. Product teams that have not thought them through before launch tend to find out during an incident.
For designers and PMs, risk assessment is not a compliance activity to hand off to a legal team. It shapes product decisions directly. A PM who finds that a content moderation model has a much higher false positive rate for non-English text has identified a risk that affects launch timing, product scope, and the design of any correction mechanism. A designer who maps what happens when an AI recommendation is wrong is doing risk assessment. Building this into the product process from the start, rather than in response to something going wrong, is what separates teams that practice responsible AI from those that talk about it.[10]
Pro Tip! AI risk assessment is most valuable before a feature ships. After launch, the cost of changing a model's behavior or redesigning an affected flow is much higher.
Topics
References
- What is responsible AI? | IBM
- Building a Responsible AI Framework: 5 Key Principles for Organizations - Professional & Executive Development | Harvard DCE | Professional & Executive Development | Harvard DCE
- Responsible AI Explained | Built In | Built In
- Building a Responsible AI Framework: 5 Key Principles for Organizations - Professional & Executive Development | Harvard DCE | Professional & Executive Development | Harvard DCE
- What is responsible AI? | IBM
- What Is Responsible AI: Principles, Frameworks & Future | iSchool | Syracuse University
- Responsible AI Principles and Approach | Microsoft AI
- What is Responsible AI - Azure Machine Learning
- What is responsible AI? | IBM
- Responsible AI Explained | Built In | Built In





