


Large language models are now a standard part of product briefs, engineering specs, and vendor evaluations across the tech industry. The vocabulary around them, tokens, embeddings, context windows, parameters, moves fast and gets used loosely. A product manager who hears "we're hitting the context limit" or "this model has 70 billion parameters" needs to know what those phrases actually mean, not to build the model, but to make good decisions about the product built on top of it.
These terms are not just technical trivia. Token count affects cost. Context window size shapes what a feature can and cannot do. The difference between training data and pretraining data explains why a model behaves well in some domains and poorly in others. Inference latency is the reason some AI features feel instant and others feel sluggish.
Understanding this vocabulary changes the quality of questions you can ask. It lets designers flag realistic constraints early, and lets product managers write requirements that engineering teams can actually evaluate. The terms in this lesson are the ones that come up most often when AI features move from concept to build.
Tokens and tokenization in LLMs
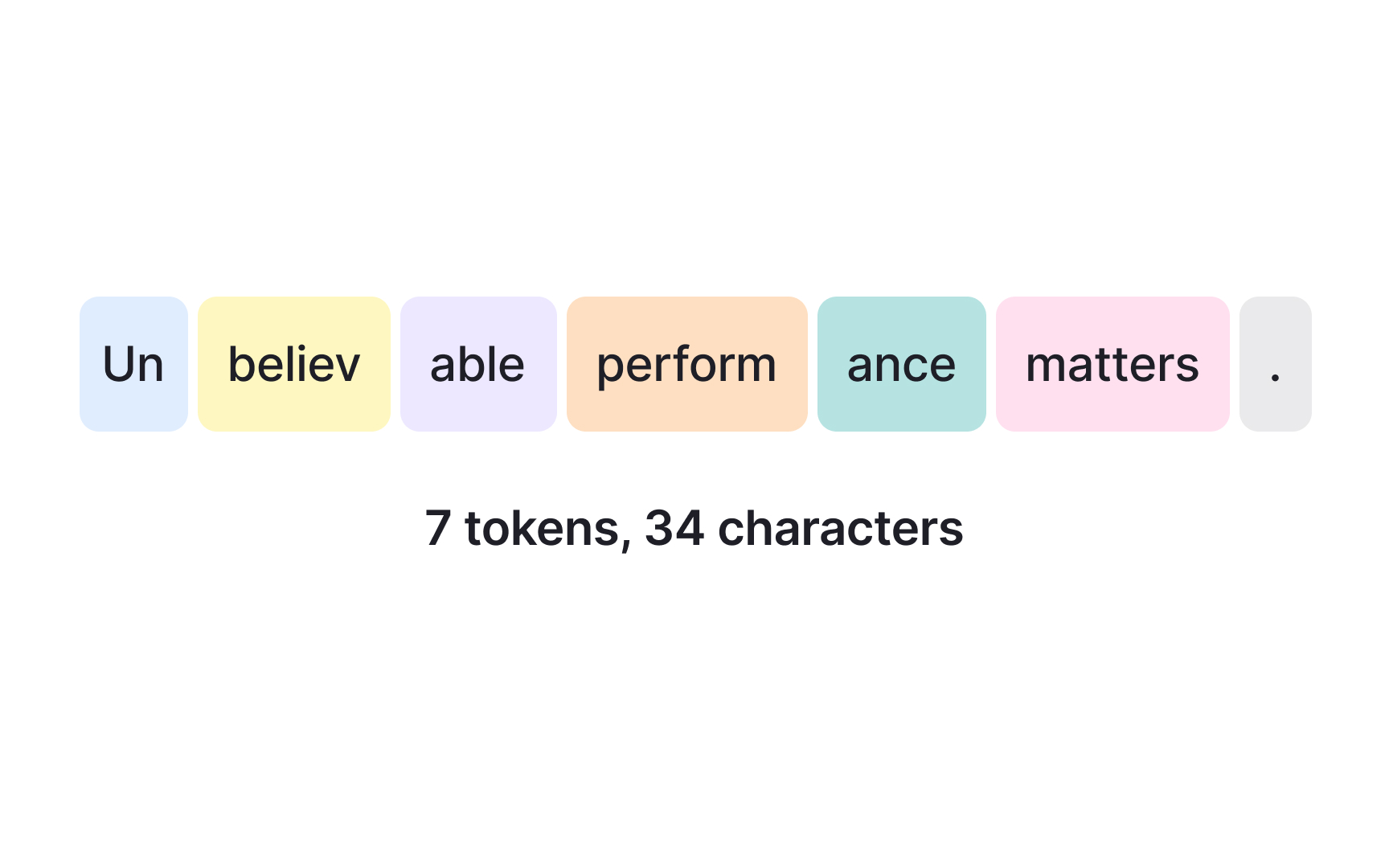
Before a large language model can process any text, it breaks the input down into small units called tokens. A token is not always a whole word. It can be a word, part of a word, a punctuation mark, or a space, depending on the model's tokenization method. The word "unbelievable," for example, might be split into "un," "believ," and "able" as 3 separate tokens. This is how LLMs handle rare or complex words without needing an infinitely large vocabulary. Tokenization is the process of converting raw text into this sequence of tokens, each assigned a unique numerical ID the model can process mathematically. Modern LLMs typically have vocabularies of 30,000 to 100,000 tokens. Every input a user sends and every output the model generates is measured and priced in tokens, not words or characters.
For product managers, token counts directly affect cost estimates and feature feasibility. A feature that summarizes long documents will consume far more tokens than a simple classification task. For designers, understanding that models process tokens rather than words explains some of the surprising edge cases: unusual names, non-English text, and technical jargon are often split into more tokens, which can degrade output quality. Knowing the term lets you ask the right questions when those edge cases appear.[1]
Embeddings in machine learning
An embedding is a numerical representation of a token, word, or piece of text as a list of numbers called a vector. When a large language model processes tokens, it converts each one into an embedding so it can perform mathematical operations on language. The key property of embeddings is that similar concepts end up with similar vectors. "King" and "queen" will have embeddings close to each other in the model's internal space. "King" and "bicycle" will be far apart.
This mathematical proximity is what allows LLMs to understand context and meaning rather than just matching exact words. When users ask a question in different words than those in a document, an embedding-based system can still find the relevant content because the vectors are close enough. It is the foundation of semantic search and retrieval-augmented generation.
Understanding embeddings explains why AI-powered search feels different from keyword search. Keyword search matches exact strings. Embedding-based search matches meaning. For a product manager reviewing a vendor's technical approach, knowing what embeddings are helps you understand claims about semantic similarity, relevance ranking, and retrieval quality, and ask sharper questions about how those properties are measured.[2]
Context window in LLMs
The context window is the maximum amount of text a large language model can process in a single interaction, measured in tokens. It includes everything the model can "see" at once: the system instructions, the conversation history, any documents passed in, and the response being generated. Once the total exceeds the context window limit, the model can no longer access earlier parts of the conversation or document.
Context window size varies significantly between models. Some have limits of a few thousand tokens, others support hundreds of thousands. A larger context window allows a model to work with longer documents, maintain coherence across a longer conversation, or process more reference material at once. But larger context windows also cost more to run and can increase response latency.
For product managers scoping AI features, the context window is a hard constraint that shapes what is actually possible. A feature that needs to summarize a 50-page contract requires a model whose context window can fit it. A customer support chatbot that needs to remember earlier messages in a session requires a context window large enough to hold them. Knowing this term helps you identify these constraints early in scoping, before engineering discovers them during implementation.[3]
Parameters in large language models
Parameters are the internal numerical values a large language model learns and stores during training. As the model processes text, it adjusts these values to improve its ability to predict what comes next. By the end of training, the parameters encode the model's accumulated knowledge of language, facts, and patterns. A model with 7 billion parameters has 7 billion such values tuned across the training process.
Parameter count is the most common way to describe model size. Larger models with more parameters are generally more capable, but also more expensive to run and slower to respond. This is why teams often choose smaller, fine-tuned models for specific tasks rather than defaulting to the largest available model: a focused smaller model can match or exceed a general large model on a narrow task, at a fraction of the cost.
A 70-billion-parameter model is not always better than a 7-billion-parameter one for a specific use case. The right question is whether the model's capabilities match the task, not which one has more parameters. That distinction protects teams from over-specifying models and running up unnecessary inference costs.[4]
Pretraining in LLMs
Pretraining is the first and most resource-intensive phase of building a large language model. During pretraining, the model is exposed to enormous volumes of text and learns to predict what comes next in a sequence. It receives no explicit instructions or labeled examples. Instead, it discovers patterns in grammar, facts, reasoning, and language structure by processing billions of examples and adjusting its parameters with each one.
The result is a model with a broad statistical understanding of language, but no specific purpose. It knows how text works across many domains without being optimized for any particular task. This pretrained state is sometimes called a base model or foundation model. Further training steps, such as fine-tuning or instruction tuning, build on this foundation to make the model useful for specific applications.
Pretraining is where most of the cost and compute in AI development sits. Training a large model from scratch can run into tens of millions of dollars and take months. For product teams, this context matters because it explains why building on top of existing pretrained models is standard practice, and why claims of training "a proprietary model from scratch" deserve scrutiny. Knowing what pretraining is helps you understand what you are actually buying when a vendor offers access to a model, and what it means when they describe it as pretrained on a specific dataset.[5]
Inference in AI models
Inference is what happens when a deployed AI model generates a response to a real input. After pretraining and any fine-tuning are complete, the model is made available for use. Each time it receives a prompt and produces an output, that is inference. The term distinguishes the live production phase of a model's use from the earlier training and development phases. Inference has direct implications for product experience. The time it takes for a model to produce a response, called inference latency, is what users feel as speed. A model that takes 5 seconds to respond to a simple question creates a noticeably worse experience than one that responds in under a second. Larger models generally have higher latency because they require more computation per response. Most AI providers charge based on inference: per token processed, per request, or per unit of compute consumed. For a product manager building a pricing model or estimating operational costs, understanding inference is foundational. It explains why cost scales with usage rather than sitting as a flat fee, and why choosing a more powerful model always involves a cost-latency tradeoff. Knowing the term lets you engage with vendor pricing documents directly rather than having to rely on engineering to translate them.
Training data and pretraining data in LLMs
Training data is the text a large language model learns from. For most modern LLMs, this consists of enormous collections of web pages, books, code, and other written material gathered before the model is built. This specific type of training data used in the first phase of model development is called pretraining data. It is what gives the model its broad knowledge of language and the world before any task-specific tuning takes place.
The content and quality of pretraining data directly shape what the model knows and how it behaves. A model trained primarily on English text will perform worse in other languages. A model trained on data with a particular cultural or political skew will reflect that skew in its outputs. Gaps in the training data produce gaps in model knowledge. This is why asking "what was this model trained on?" is one of the most important questions a product team can ask when evaluating an AI provider. For a product designer building a feature that serves a diverse user base, understanding pretraining data explains why some AI outputs feel more relevant or accurate for some users than others. For a product manager writing evaluation criteria, it provides a basis for asking vendors about data sources, cutoff dates, and known coverage gaps. The term is also relevant when a model confidently produces outdated information: its pretraining data has a cutoff, and anything after that date simply does not exist in its knowledge.[6]
References
- How LLMs Work: Tokens, Embeddings, and Transformers | Dremio | Dremio
- How LLMs Work: Tokens, Embeddings, and Transformers | Dremio | Dremio
- LLM context windows: what they are & how they work | Redis
- What Are Large Language Models (LLMs)? | IBM
- How do Transformers work? · Hugging Face
- How do Transformers work? · Hugging Face





