


Supervised, unsupervised, reinforcement. These 3 terms come up constantly in conversations about AI products, yet most designers and product managers treat them as interchangeable labels for "the AI part." They are not. Each describes a fundamentally different way a system learns, which means different data requirements, different failure patterns, and different implications for what the product can and cannot do.
The vocabulary gap shows up in real ways. A product manager who does not know what labeled data is cannot meaningfully evaluate whether a vendor's model is a good fit for a use case. A designer who cannot distinguish classification from clustering will struggle to understand why a feature groups users in one product and flags individual actions in another. These are not abstract concepts. They are the terms that describe what is actually happening inside the AI features teams build and ship.
Knowing the terminology does not require a background in statistics or data science. It requires understanding what each term means, what it implies, and how to use it accurately when it comes up in a brief, a review, or a vendor conversation.
Supervised learning in machine learning
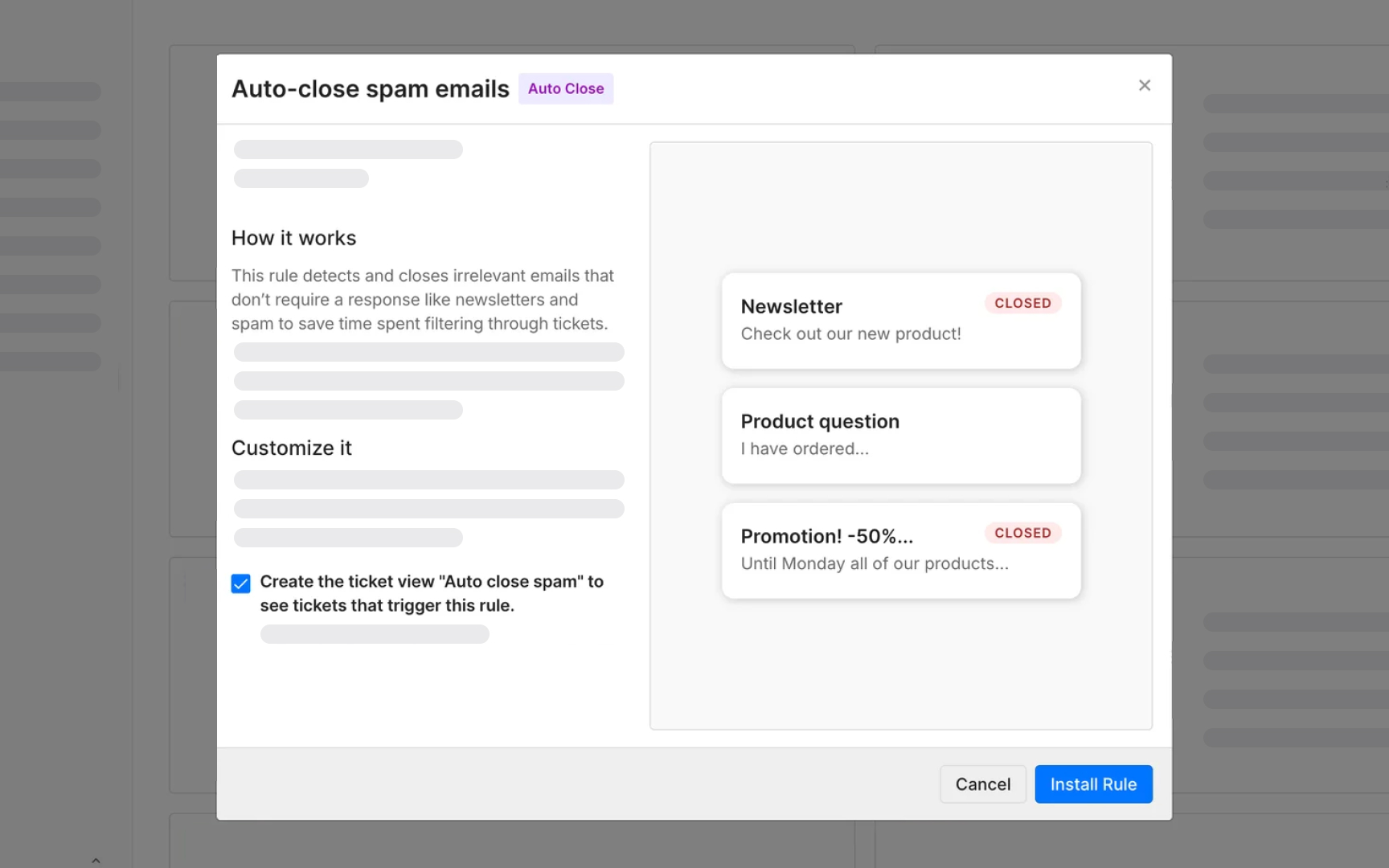
Supervised learning is a type of machine learning where a model is trained on a dataset in which every example has already been labeled with the correct answer. The model learns by studying these input-output pairs, identifies patterns, and builds internal logic that allows it to predict the correct output for new, unseen inputs. The "supervised" part refers to the human effort involved in providing those correct answers before training begins.
The contrast with rule-based systems makes the term clearer. A rule-based spam filter works by checking every incoming email against conditions a developer wrote by hand. If the subject line contains "50% off" or the sender matches a known newsletter domain, the email gets closed. A supervised learning model produces the same sorting behavior differently: it is trained on thousands of emails humans labeled as spam or not spam, and learns which patterns predict each label on its own. The rules are not written. They are learned.
That distinction has direct product implications. A rule-based system breaks when it encounters spam it was not programmed to recognize. A supervised model can generalize to variations it has never seen, because it learned underlying patterns rather than a fixed checklist. The trade-off is that building it requires labeled data, ongoing evaluation, and deliberate retraining when real-world behavior changes.[1]
Labeled data in machine learning
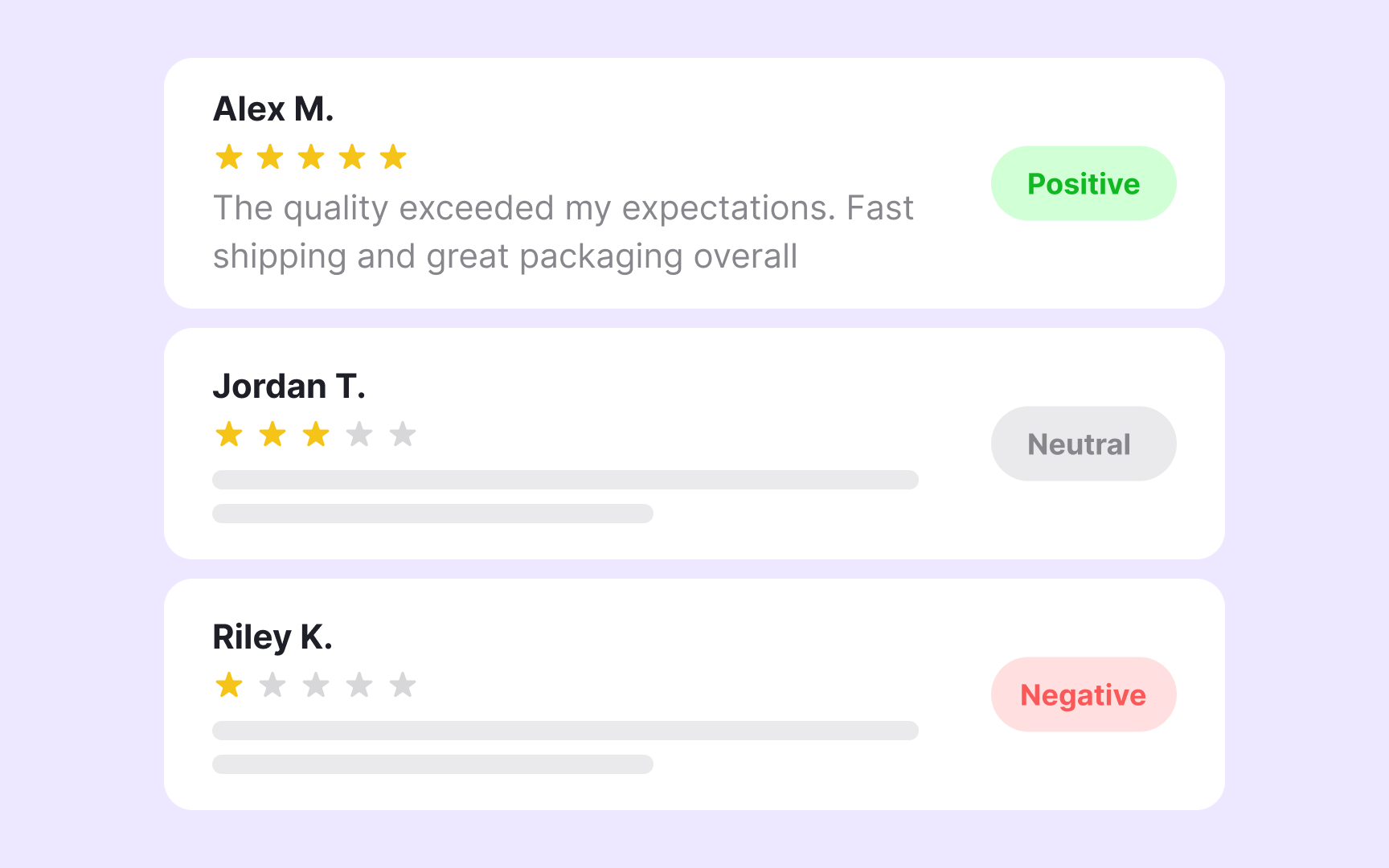
Labeled data is a dataset in which each example has been tagged with a meaningful annotation that tells the model what the correct output should be. A set of product images labeled "defective" or "acceptable," a collection of customer reviews tagged "positive," "neutral," or "negative," or a library of medical scans marked with a diagnosis are all labeled datasets. The labels are what make supervised learning possible. Without them, the model has no ground truth to learn from.
Creating labeled data is not a technical task. It is a human one. Annotators, whether specialist teams or general contributors, review raw data and apply tags based on defined criteria. The process is slow, expensive, and prone to inconsistency. A single image dataset used to train a computer vision model can require tens of thousands of individual human judgments. This is why labeled data is often described as one of the most valuable and costly inputs in any supervised learning project.
For designers and product managers, the term carries a practical implication. When a team is evaluating whether to build or buy an AI feature that uses supervised learning, the question of labeled data is central. Where does it come from? How much exists? Is it representative of the actual user population? A model trained on labeled data that skews toward one type of user, one language, or one set of conditions will reflect those constraints in its outputs. Labeled data is not neutral. It encodes the judgments of whoever did the labeling.[2]
Pro Tip! Garbage in, garbage out" is the oldest rule in data work. For supervised learning, the quality of the labels is the quality of the model.
Classification and regression in supervised learning
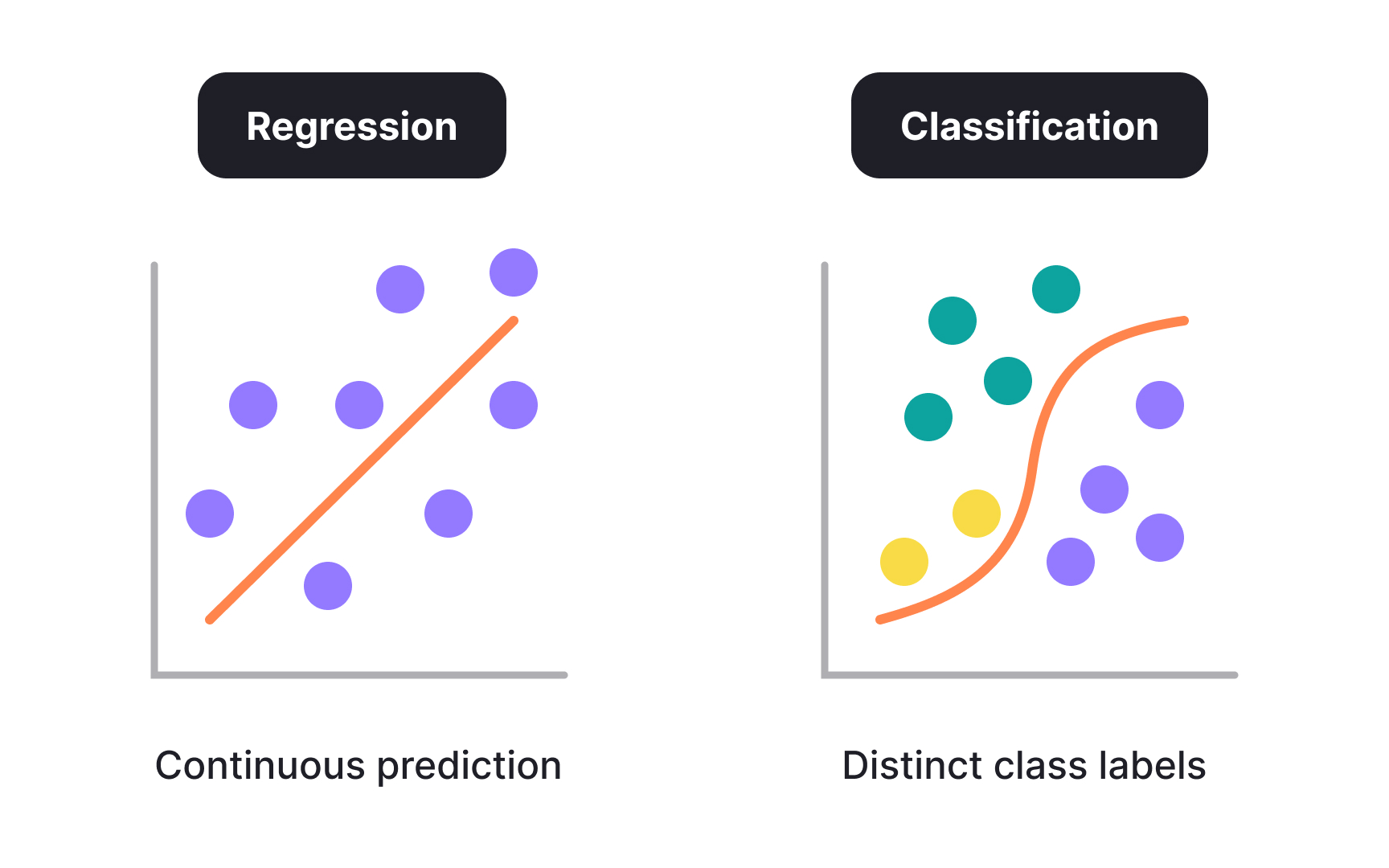
Supervised learning covers two distinct task types that produce fundamentally different kinds of output:
- Classification is the task of predicting which category an input belongs to. The output is always a label from a predefined list: spam or not spam, fraudulent or legitimate, low risk or high risk.
- Regression predicts a number rather than a category. The keyword is continuous: the output is not chosen from a predefined list but can land anywhere along a scale. A model predicting property prices does not choose between "cheap," "mid-range," and "expensive." It outputs a specific value, say 347,000, derived from patterns it found in historical data. That value sits on a continuous scale with no fixed steps between the lowest and highest possible output.
What separates regression from classification at a fundamental level is that the number can be any point on an unbroken range. For product teams, the distinction changes how outputs need to be handled. Classification outputs are discrete and actionable. Regression outputs are probabilistic estimates that carry uncertainty. A predicted churn rate of 68% or a forecasted delivery time of 3.2 days are not guarantees. Designing around them requires range handling, rounding decisions, and careful thinking about how to surface uncertainty without creating false precision.[1]
Unsupervised learning and clustering in machine learning
Unsupervised learning is a type of machine learning where the model is trained on data that has not been labeled. There are no predefined correct answers. Instead of learning to predict a specific output, the model explores the data and identifies structure, patterns, or groupings on its own. The "unsupervised" in the name reflects the absence of human-defined labels guiding what the model should find.
Clustering is the most common technique in unsupervised learning. It groups data points together based on similarity, without being told in advance what the groups should be. A product team might run a clustering algorithm on behavioral data to discover that users naturally fall into 4 distinct usage patterns, none of which the team had predicted or named in advance. The insight came not from asking "which category does this user belong to?" but from letting the model find the structure in the data on its own. This is what separates unsupervised learning from supervised learning at a practical level. Supervised learning needs labeled data, which is expensive to produce. Unsupervised learning works with raw, unlabeled data, which is far easier to collect. The trade-off is that outputs like clusters are harder to evaluate because there is no ground truth to measure them against. Clusters are not facts. They are patterns the model surfaced, and they always need human interpretation before informing a product decision.[3]
Pro Tip! User segments discovered through clustering are hypotheses, not ground truth. They need human interpretation before they can meaningfully inform a product decision.
Reinforcement learning and the reward loop
Reinforcement learning is a type of machine learning where a system, called an agent, learns by interacting with an environment and receiving feedback in the form of rewards or penalties. There is no labeled dataset to learn from. Instead, the agent tries different actions, observes the results, and gradually adjusts its behavior to maximize the total reward it accumulates over time. The term "reinforcement" refers to the strengthening of behaviors that lead to positive outcomes.
The classic analogy is training a dog. The dog tries a behavior, gets a treat if it was correct and no treat if it was not, and over time learns which behaviors produce rewards. Reinforcement learning systems work the same way, at scale and speed that no animal trainer could match. Early applications were in game-playing AI: systems trained to play chess or Go by playing millions of games against themselves and learning which moves led to wins.
In product work, reinforcement learning is less visible but increasingly present. Recommendation systems that optimize for engagement use reinforcement learning to learn which content to surface at which moment. Chatbot systems that improve over time based on user feedback signals often use reinforcement learning under the hood. For product managers and designers, the term matters because it signals a system that is actively optimizing for a defined reward. The question to ask is: what is the reward function, and does it actually align with the outcomes the product intends to create for users?[4]
Semi-supervised learning
Semi-supervised learning is a machine learning approach that combines a small amount of labeled data with a large amount of unlabeled data during training. The model uses the labeled examples to establish a foundation of correct outputs, then applies that understanding to find patterns in the unlabeled data and extend what it has learned. It sits between supervised and unsupervised learning, drawing on the strengths of both.
The reason this approach exists is practical. Labeled data is expensive and time-consuming to produce. Unlabeled data is abundant and cheap to collect. Semi-supervised learning allows teams to train more capable models without the cost of labeling everything. A speech recognition model trained on a small labeled corpus of transcribed audio and a large unlabeled corpus of raw recordings is a common example. The labeled data anchors the model. The unlabeled data extends its reach.
For product teams, the term is most relevant when evaluating AI vendors or reviewing technical proposals. A system described as using semi-supervised learning is making a specific claim about its data strategy: that it relies on a mix of human-labeled examples and pattern-finding across unlabeled data. Knowing the term allows a product manager to ask how much of the training data was labeled, who labeled it, and how the model's behavior was validated, given that most of the training data lacked ground truth. Those questions go directly to reliability, coverage, and edge case behavior.[5]
Topics
References
- Types of Machine Learning: Supervised, Unsupervised and More | DigitalOcean
- What is Labeled Data?
- Types of Machine Learning: Supervised, Unsupervised and More | DigitalOcean
- 3 types of machine learning in 2026: what they are, how they work together, and which one you actually need | Pecan AI
- 4 Types of Machine Learning Models Explained | Search Enterprise AI





