


When a product team ships an AI feature, a lot of what determines the quality of the output is not the model itself but how it is instructed. The way a prompt is written, what context is given upfront, how creative or conservative the model is set to be. All of these are decisions that product managers and designers increasingly influence directly. But without the right vocabulary, those decisions are made by guesswork. Terms like prompt engineering, system prompt, and temperature describe the levers that shape how a model responds. Hallucination names the failure mode that erodes user trust most quickly. Few-shot and zero-shot learning describe how much guidance the model is given before it performs a task. Chain-of-thought prompting names a technique that makes complex model reasoning more reliable.
These are not engineering-only concepts. A product manager writing a spec for an AI writing tool needs to know what a system prompt is and what it can and cannot control. A designer evaluating why an AI feature produces inconsistent outputs needs to understand what temperature does. Knowing this vocabulary means fewer handoffs, fewer misunderstandings, and more ownership over the quality of what gets shipped.
Prompt engineering in LLMs
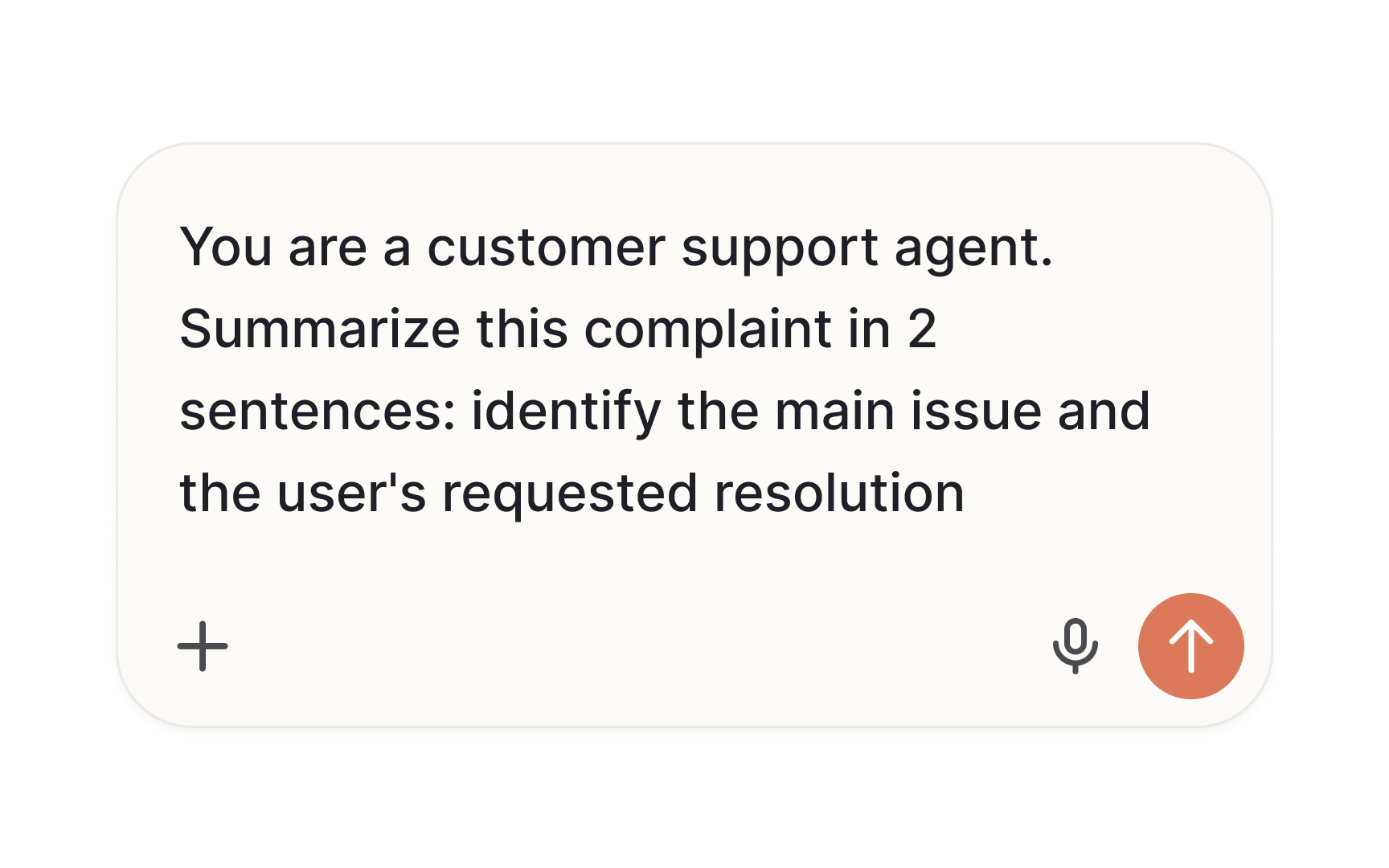

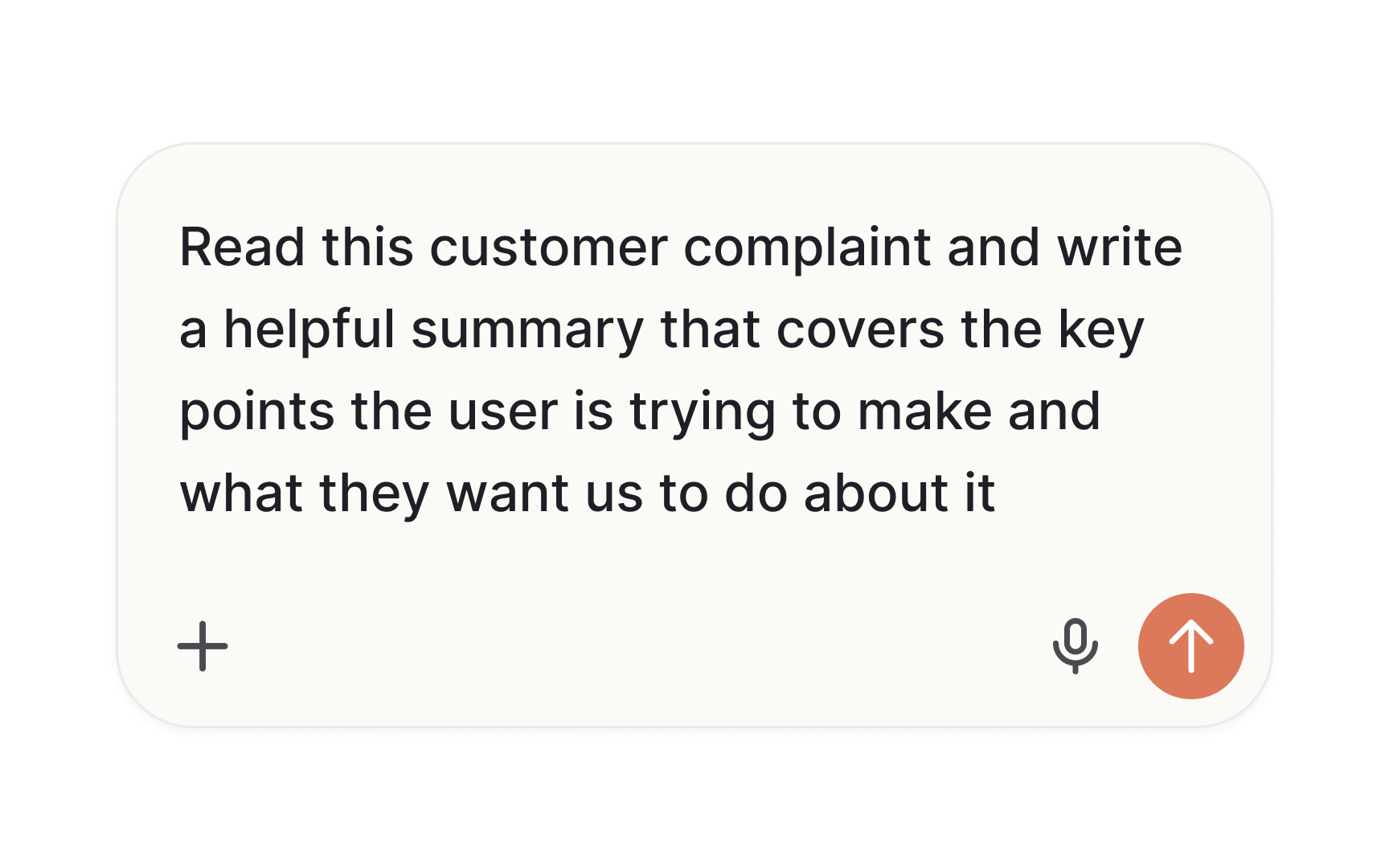

Prompt engineering is the practice of designing and refining the inputs given to a large language model to improve the quality and consistency of its outputs. A prompt is the text users or system send to the model. Prompt engineering is the deliberate work of making that text as effective as possible for a given task. It includes choosing how to frame a question, what context to include, what format to request, and how specific to be about the desired output.
The core insight behind prompt engineering is that model output quality tracks prompt quality. A vague prompt produces vague results. A well-structured prompt with clear context, a defined role, and a specific output format produces results that are far more useful and consistent. This is why teams that use AI tools effectively invest time in developing, testing, and refining their prompts rather than treating them as throwaway inputs. Understanding the term reframes prompt-writing from something casual into something worth designing and testing with the same rigor as any other feature component.[1]
System prompt in LLMs
A system prompt is a set of instructions given to a large language model before any user interaction begins. It is not visible to end users, but it shapes every response the model produces within that session. It might define the model's role, set constraints on what it should and should not say, specify a tone, or establish the context in which it is operating.
System prompts are one of the primary tools product teams use to customize a general-purpose model for a specific product experience. The same underlying model can behave very differently depending on what its system prompt contains. A model with no system prompt responds like a general assistant. The same model instructed to act as a billing support agent, answer only questions about invoices and payments, keep responses concise, and address users formally will refuse off-topic questions and never slip into casual language.
This is why 2 products built on the same model can feel completely different to users. The system prompt is where much of the product design work for an AI feature actually lives, and knowing the term helps teams have more precise conversations about ownership, testing, and quality control.[2]
Temperature in LLMs
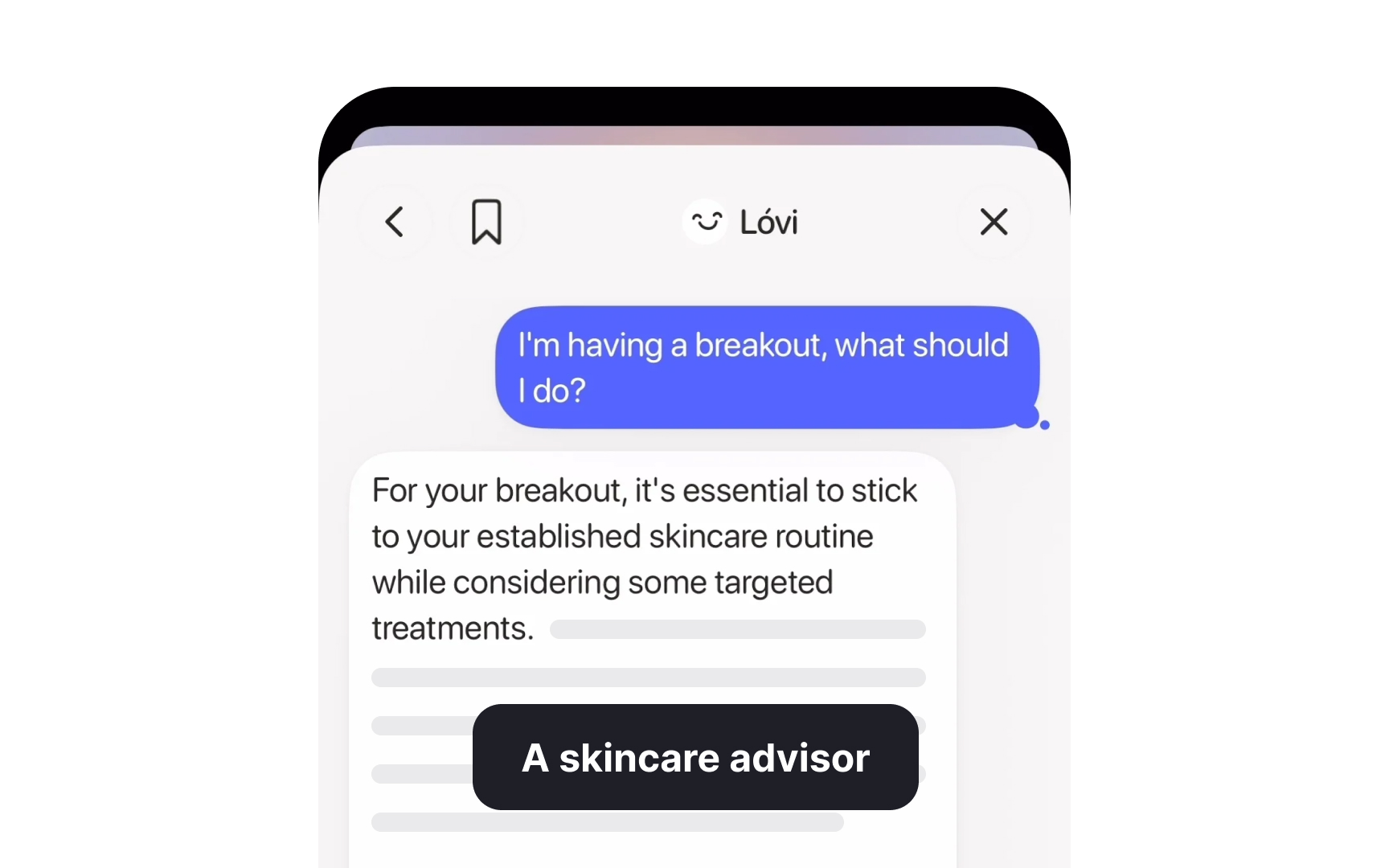
Temperature is a setting that controls how varied or predictable a large language model's outputs are. At low temperature settings, the model consistently chooses the most statistically likely next token, producing outputs that are focused, repetitive, and reliable. At high temperature settings, it introduces more randomness into its choices, producing outputs that are more varied, surprising, and sometimes more creative, but also more prone to errors.
The name comes from physics, where temperature describes the energy level of a system. In LLMs, higher temperature means more "energy" in the selection process, more willingness to pick less probable tokens. Lower temperature means the model sticks closer to what it has learned is most likely. A temperature of zero produces the same deterministic output every time for a given input. For product teams, temperature is a practical design decision. A customer support bot that answers factual questions needs a low temperature to stay accurate and consistent. A creative writing assistant benefits from a higher temperature to produce more varied and interesting suggestions. When a designer notices that an AI feature gives wildly different answers to the same question on different attempts, temperature is often part of the explanation. Knowing the term lets you name the problem and discuss the tradeoff directly with engineering.[3]
Hallucination in AI models
Hallucination refers to outputs generated by a large language model that are fluent and confident but factually incorrect or entirely fabricated. The model does not flag uncertainty or signal that it is guessing. It produces text that sounds authoritative because it is optimized to generate statistically plausible sequences of tokens, not to verify facts. A hallucinating model might invent a citation, state an incorrect date, or describe a product feature that does not exist.
The root cause is the nature of how LLMs work. They predict what text is likely to come next based on patterns in training data. When the correct answer falls outside those patterns, or when the model lacks the information needed, it fills the gap with plausible-sounding text rather than admitting ignorance. This is not deception. It is a structural property of how these systems generate output.
For product managers, hallucination is a critical risk to scope for in any AI feature that produces factual content. Copy, legal text, medical information, product descriptions: any domain where accuracy matters requires explicit mitigations. For designers, it shapes how error states should be handled and whether users should be prompted to verify AI-generated content. Knowing the term precisely, and being able to explain why it happens, is the foundation for having productive conversations with engineering about where and how to reduce it.[4]
Few-shot learning in LLMs

Few-shot learning is a prompting technique where a small number of examples are included in the prompt to show the model what kind of output is expected. Instead of describing the task in abstract terms, the user provides 2 to 5 worked examples that demonstrate the input-output pattern. The model uses those examples to infer what is being asked and applies the same pattern to the new input.
The technique is useful because it requires no retraining or model changes. The examples are simply part of the prompt, and they significantly improve output consistency and accuracy for structured tasks. A copywriter drafting client proposals, for example, might include 3 examples of past proposals in the prompt so the model matches the expected tone and structure before generating a new one.
Understanding the term helps users recognize when an inconsistency in AI output is a prompt design problem, specifically a lack of examples, rather than a fundamental model limitation.[5]
Zero-shot learning in LLMs
Zero-shot learning is when a large language model performs a task it has not been given any examples for, relying entirely on its pretrained knowledge and the instructions in the prompt. The "zero" refers to the number of examples provided: none. The model is expected to understand the task from description alone and generate an appropriate response without being shown what the output should look like.
Modern LLMs are capable of strong zero-shot performance on many tasks because they have been exposed to such a large variety of text during pretraining. Asking a model to "summarize this paragraph in one sentence" or "classify this review as positive or negative" typically works without examples because the model has encountered those task types many times in its training data. Zero-shot and few-shot learning are often discussed as a pair because they represent a choice: how much guidance does this task require? Knowing the terms lets you diagnose output quality issues more precisely.[6]
Chain-of-thought prompting
Chain-of-thought prompting is a technique where the model is instructed or shown how to reason through a problem step by step before producing a final answer. Rather than jumping directly to a conclusion, the model is guided to lay out intermediate reasoning, which makes the overall output more reliable for tasks that involve multiple steps, logic, or calculation.
The technique emerged from research showing that LLMs make more errors when asked to answer complex questions directly. When the same questions are framed in a way that encourages step-by-step reasoning, accuracy improves significantly. In practice, this can be done by including a phrase like "think step by step" in the prompt, or by providing few-shot examples that demonstrate reasoned answers rather than direct ones.
Topics
References
- The product manager's guide to prompt engineering | Product-Led Alliance | Product-Led Growth
- Prompt Engineering Blurs the Line Between PMs and Engineers
- LLM Settings | Prompt Engineering Guide
- Understanding Hallucination In LLMs: A Brief Introduction – The GDELT Project
- AI prompt engineering as a product manager | Alan Wright
- AI prompt engineering as a product manager | Alan Wright





